PeerLLM v0.7.6: The Fastest, Smartest, and Most Purposeful Version Yet
🚀 PeerLLM v0.7.6: The Fastest, Smartest, and Most Purposeful Version Yet
PeerLLM version 0.7.6 is here, bringing major improvements in speed, control, and reliability.
From GPU breakthroughs to ethical orchestration and developer APIs, this release represents the strongest step yet toward a global, decentralized AI network that serves humanity.
🧩 0/ A Complete Host Rewrite: Faster, Native, and Smoother
This release includes a full rewrite of the PeerLLM Host for better performance, stability, and direct integration with native LLM libraries.
The new architecture:
- Uses native bindings for llama-cpp and other local model runners
- Reduces startup latency and memory overhead
- Improves cross-platform consistency across Windows, macOS, and Linux
- Enables cleaner background processes for multi-model support and GPU acceleration

When I started PeerLLM, I dreamed of a network that could unite devices of every kind under one vision: decentralized intelligence for everyone. Seeing the Host run seamlessly across Windows, macOS, and Linux for the first time felt like that dream taking shape. This photo means more than compatibility — it’s proof that a connected, ethical, human-centered AI ecosystem is possible.
This rewrite sets the stage for faster response times and modular orchestration.
⚡ 1/ GPU Performance: From 190ms to 9ms per Token
High-end Hosts are now breaking speed records.
With optimized GPU utilization, threading, and token streaming, some Hosts have gone from 1 token per 190 milliseconds to 1 token per 9 milliseconds, the fastest ever recorded in the PeerLLM network.
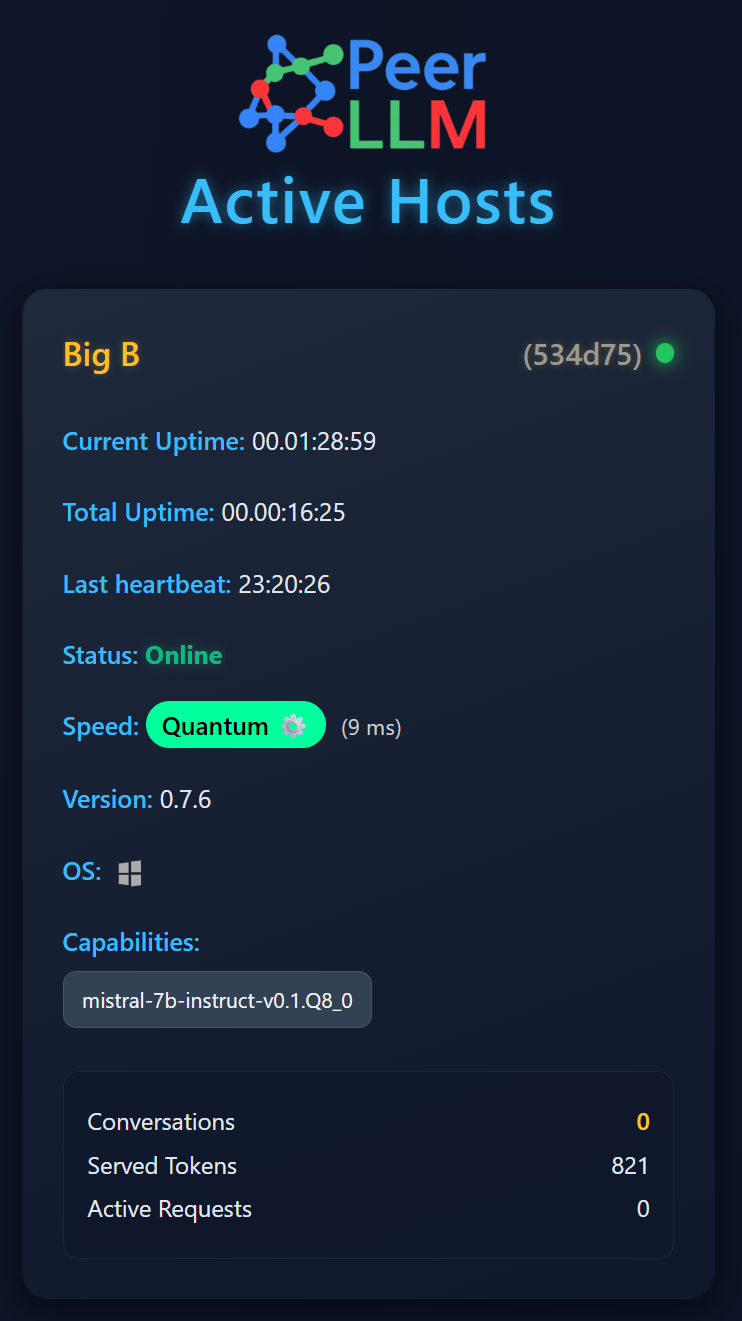
If your hardware supports it, expect a major jump in throughput and responsiveness.
🧭 2/ Menus: Explore, Configure, Test, and Connect
PeerLLM Host v0.7.6 introduces a full desktop-style menu system, making it easier to navigate and manage your Host.
Menus now exist on Windows, Linux, and macOS, each following the conventions of their platform.
🪟 2.1 Menu Availability
Windows and Linux
The main menu appears at the top of the Host window.

macOS
The menu appears in the native system bar at the top left of the screen.

📂 2.2 Open LLMs Folder
This option opens the folder containing your downloaded models.
Use it to quickly check your model files, verify installation size, or manage multiple .gguf models.
Default model directory:
- Windows:
C:\Users\<username>\AppData\Roaming\peerllm-host-electron\LLMs\ - macOS:
~/Users/<username>/Library/Application Support/peerllm-host-electron/LLMs/ - Linux:
~/home/<username>/.config/peerllm-host-electron/LLMs/
⚙️ 2.3 Open Configuration Folder
This option opens your configuration directory, where your peerllm-host-config.json file is stored.
You can review or back up your host details, version history, or settings from here.
Typical configuration path:
- Windows:
C:\Users\<username>\AppData\Roaming\peerllm-host-electron\LLMs - macOS:
~/Users/<username>/Library/Application Support/peerllm-host-electron/ - Linux:
~/home/<username>/.config/peerllm-host-electron/
🧪 2.4 Test Host
Use this option to run a full diagnostic test of your Host setup.
It verifies:
- Model load speed
- Token generation throughput
- Memory and GPU usage
- Latency per token
The test window displays your performance metrics in real time, confirming your Host is ready to serve compute.
💬 2.5 About PeerLLM
This section keeps you connected with the PeerLLM community.
It includes:
- Current app version
- Links to the PeerLLM website, community pages, and GitHub repo
- Contact information for feedback and updates
The About dialog is your quick link to stay informed, supported, and involved.
✅ 2.6 Why This Matters
This new menu system is more than a design feature.
It creates a sense of completeness and professionalism, giving Hosts a consistent experience across platforms.
PeerLLM now feels like a native application — simple, organized, and connected.
🪵 3/ Logs: Smarter Diagnostics
Every Host now records detailed logs that capture issues, crashes, and runtime events.
These logs help diagnose Hosts that fail to serve compute and make troubleshooting easier.
📂 Where to Find Logs
PeerLLM uses Electron’s app.getPath("userData") which automatically adjusts to your system:
- Windows:
C:\Users\<username>\PeerLLM\logs - macOS:
~/Library/Application Support/PeerLLM/logs - Linux:
~/.config/PeerLLM/logs
Each log includes timestamps, events, and performance traces that help with debugging and transparency.
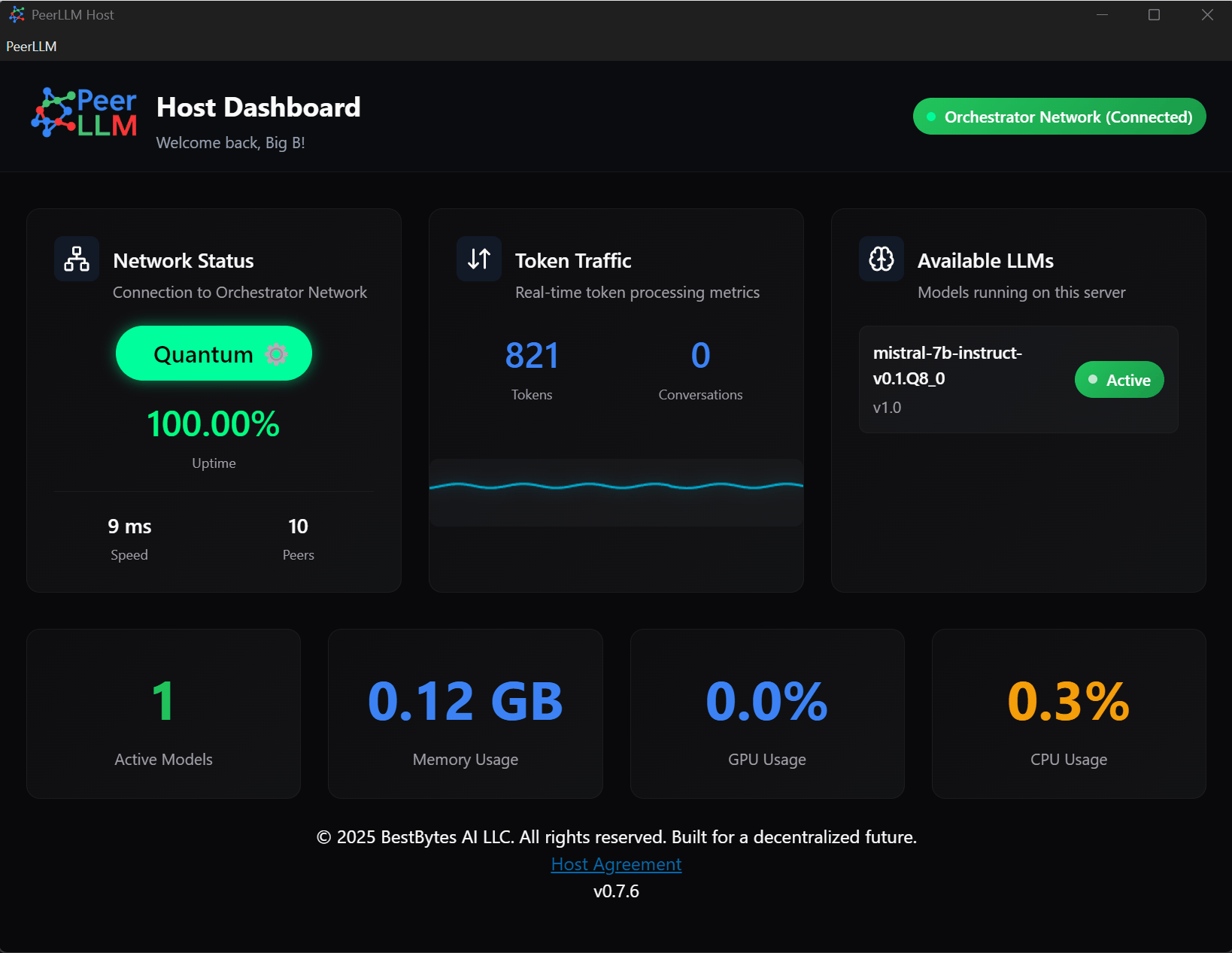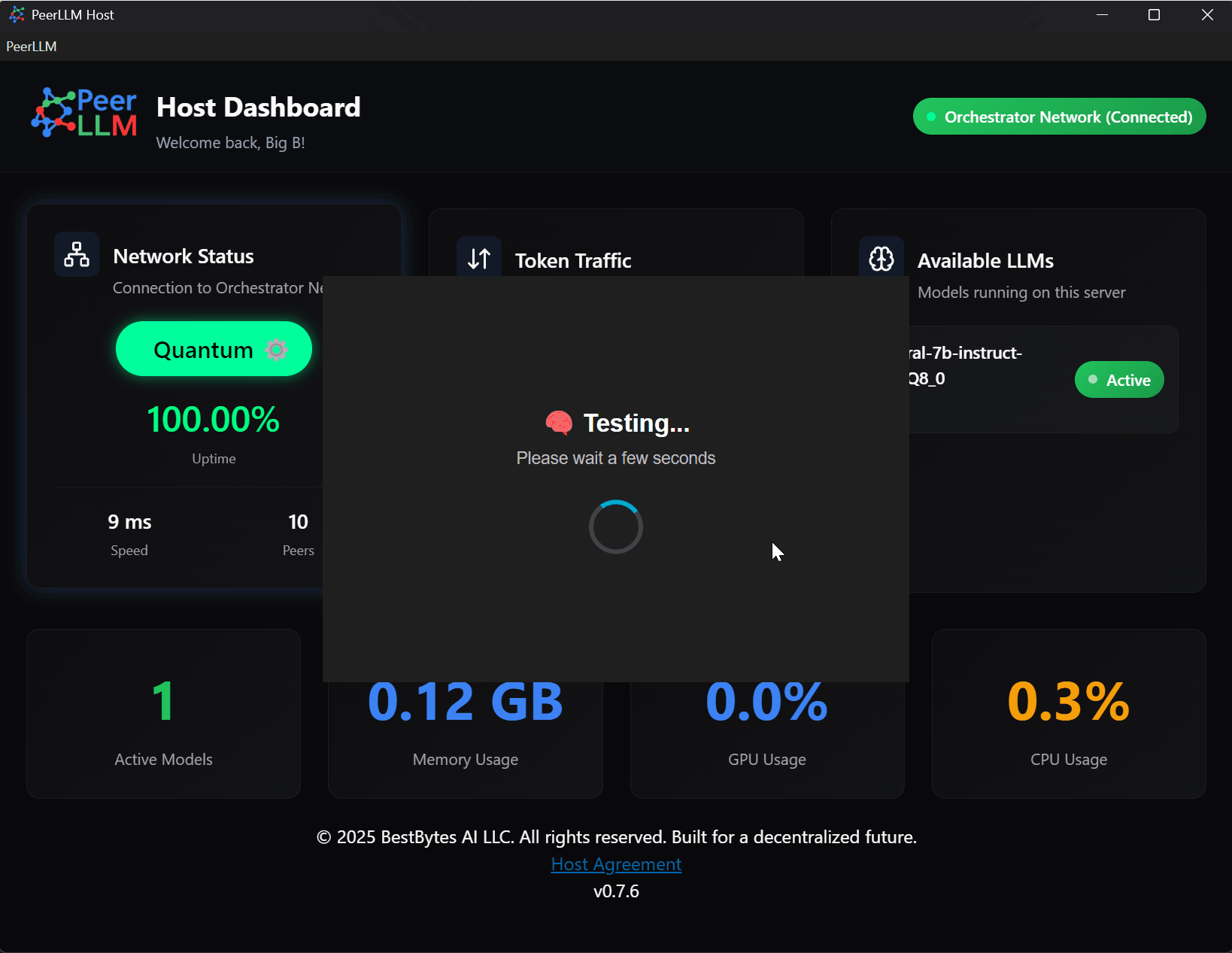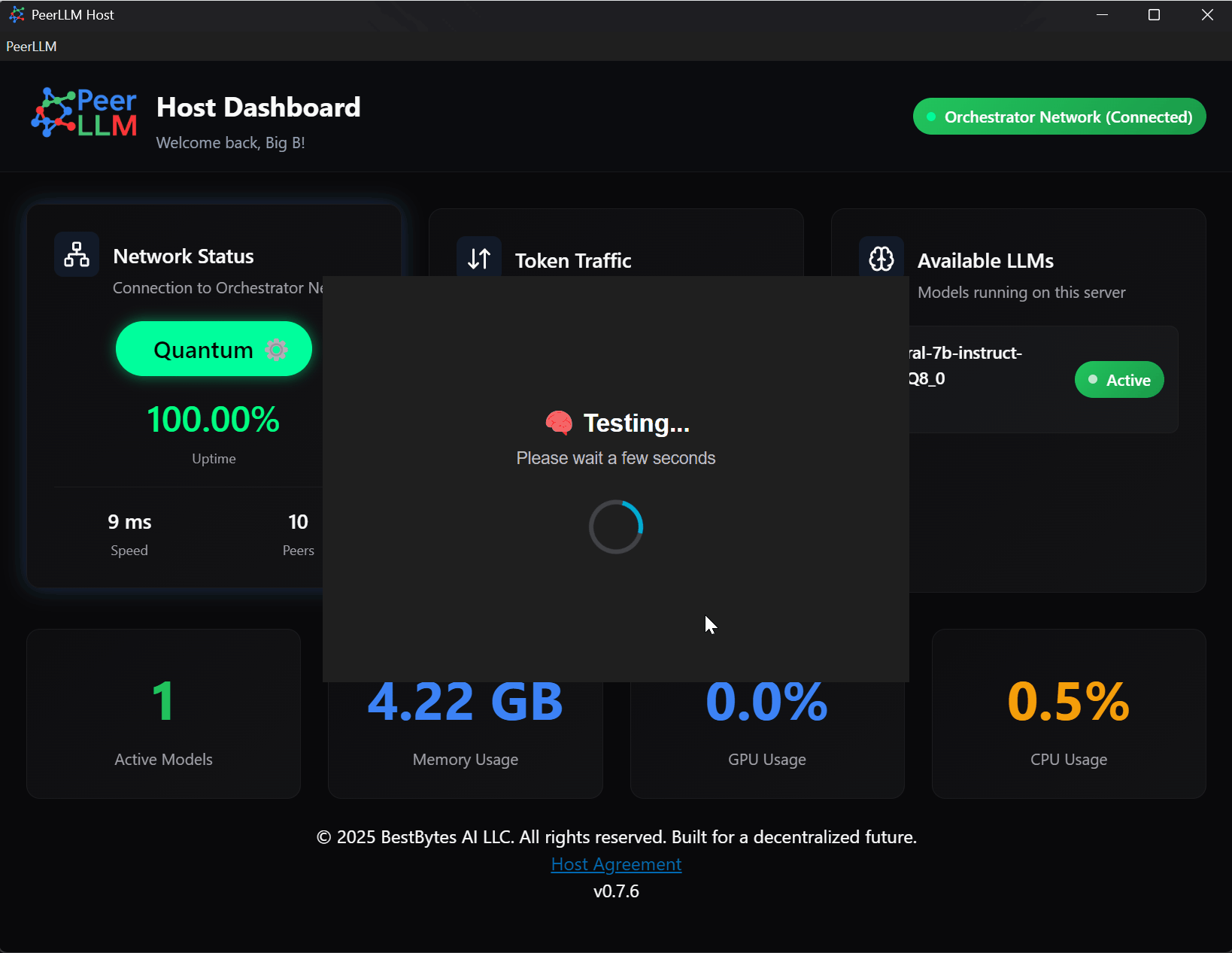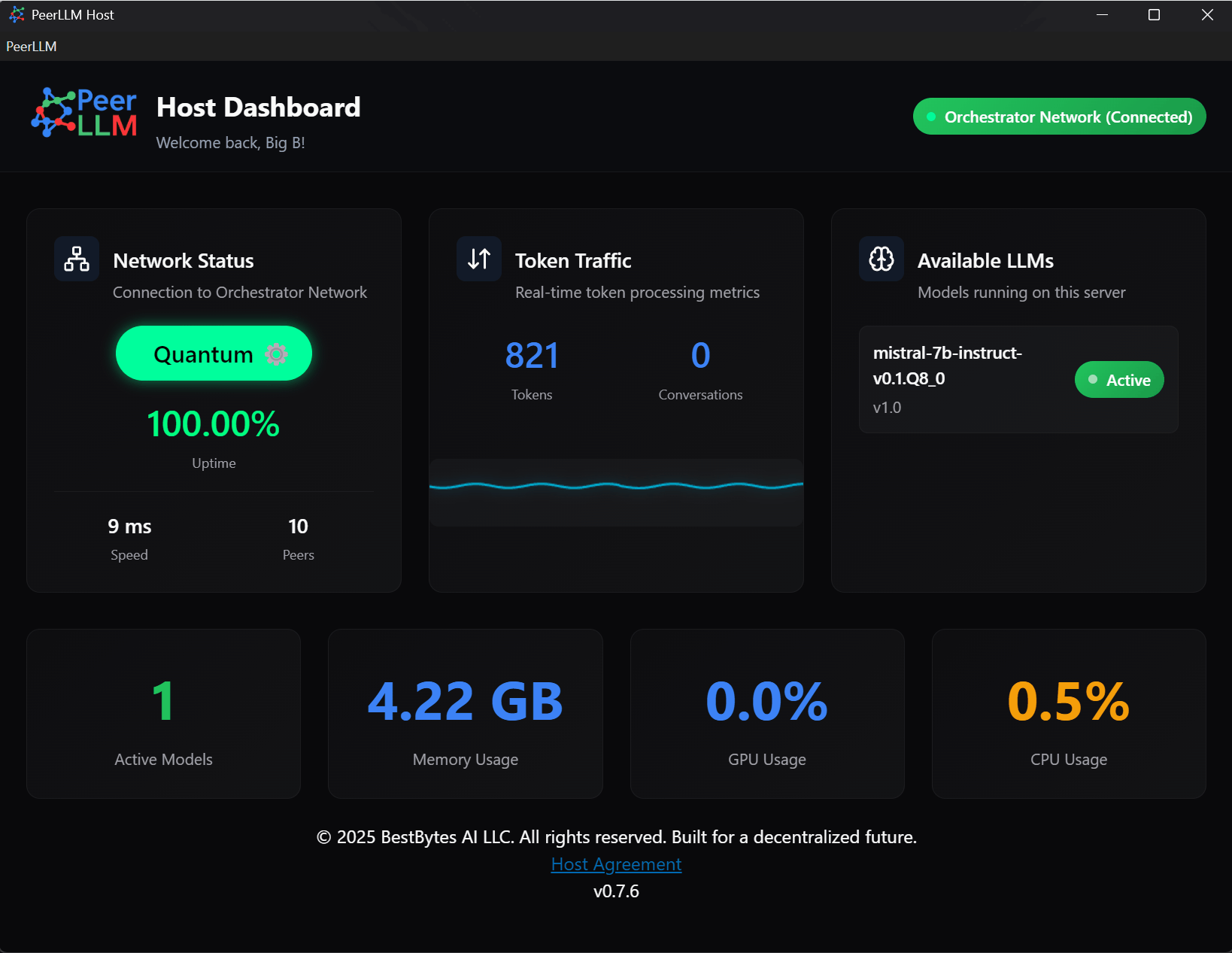
🧠 4/ Smarter Performance and Monitoring
The heartbeat and telemetry systems have been redesigned to reduce CPU usage and unnecessary checks.
PeerLLM now aggregates and caches system data, improving performance by up to 40% while tracking:
- GPU and CPU usage
- Memory trends
- Network health
- Latency to the Orchestrator
The result is smoother, more efficient hosting.
🌐 5/ Reduced Remote Calls
Host communication with the Orchestrator has been optimized.
PeerLLM now syncs data in intelligent bursts, lowering bandwidth consumption while keeping information up to date in near real time.
This change improves efficiency as the network continues to grow.
💎 6/ UI and Visual Refinements
Dialogs such as Testing, Loading, and About have been redesigned for better consistency across Windows, macOS, and Linux.
The result is a cleaner, more modern look and feel.
🆙 7/ Version Check and Update Awareness
The Host now shows both your current and latest available version.
If a new release is available, PeerLLM will notify you and guide you to download it, keeping all Hosts in sync and performing optimally.
🧮 8/ Smarter Caching Layer
System and network data are now cached locally.
If your internet connection drops temporarily, PeerLLM continues to function and maintain stable reporting without interruption.
🔒 9/ Security and Privacy Enhancements
PeerLLM now uses privacy-preserving telemetry.
Sensitive information like machine names or file paths is masked before being sent to the Orchestrator, ensuring only essential, anonymous data is transmitted.
🔭 10/ Future-Ready for Multi-Model Hosting
The Host architecture now supports upcoming multi-model capabilities.
Soon, a single machine will be able to serve multiple models such as Mistral 7B, Mixtral, or Phi-3, all managed intelligently by PeerLLM.
🧬 11/ Orchestrator Governance: Safety, Privacy, and Purpose
At the Orchestrator level, PeerLLM now enforces governance policies to ensure all compute and communication align with the PeerLLM Standard of Ethics.
LLMs can be open and unpredictable, but PeerLLM guarantees that every computation contributes to the survival, evolution, and fulfillment of humanity.
The Orchestrator:
- Enforces safety and privacy compliance
- Protects against harmful or exploitative prompts
- Ensures responsible compute distribution
PeerLLM is more than a network. It is an ethical intelligence ecosystem.
🔑 12/ API v2.0: Secure Access for Builders
Developers can now build directly on the PeerLLM Network using API v2.0.
Highlights:
- API Keys securely requested through the community
- Granular access controls for fair and auditable use
- Precision endpoints for querying Hosts and orchestrated compute
- Safety filters that ensure all activity aligns with PeerLLM principles
API v2.0 makes it easier than ever to build responsibly on decentralized AI infrastructure.
⚙️ 13/ Dynamic Host Profiles: Smarter, Personalized Performance
Each Host now develops a performance fingerprint.
PeerLLM remembers your CPU, GPU, and latency characteristics, improving how the network routes compute jobs to you.
This adaptive system learns and optimizes Host matching automatically over time.
🧪 14/ Enhanced Testing Dialog: Verify Your Host’s Health
The Test Host feature now provides detailed insights including:
- Model load times
- Token throughput
- GPU memory usage
- Average latency per token
This makes it easy to confirm your Host is ready for production workloads.
🛠️ What’s Next: The Road to Public Release
The next phase of PeerLLM is focused on scaling the network and empowering Hosts worldwide.
0/ Accounts and Verification
Manage multiple Hosts under a single verified account.
1/ Payments and Earnings
Begin payment processing in the United States, then expand globally so Hosts can earn real income for serving AI compute.
2/ PeerLLM Hardware
We are prototyping dedicated devices that can run PeerLLM out of the box.
Buy one, plug it in, and start earning.
3/ Offline Hosting
Run PeerLLM entirely offline and connect locally without the Orchestrator.
Build your own private AI services for home or business.
4/ Private Hosting
Host private compute accessible only to specific users or organizations.
Perfect for secure, invite-only microclouds.
❤️ A Thank You to the Community
This release would not exist without our amazing community of Hosts, testers, and supporters.
Every idea, bug report, and contribution strengthens PeerLLM.
Together, we are building something extraordinary.
👕 Want a PeerLLM Shirt?
If you want a PeerLLM shirt (and yes, they look awesome), reach out in The Standard Community.

We would love to send you one for free as a thank-you for being part of this journey. ❤️
🧠 Ready to Become a Host?
Join the decentralized AI revolution today.
Sign up as a Host and start serving real compute from your machine.
Click here to start a join submission form
Download PeerLLM Host v0.7.6
- 🪟 Windows (x64): Download
PeerLLM-Host-Setup-x64.exe - 🍎 macOS (Apple Silicon / arm64): Download
PeerLLM-Host-arm64.dmg - 🍏 macOS (Intel / x64): Download
PeerLLM-Host-x64.dmg - 🐧 Linux (x64 / AppImage): Download
PeerLLM-Host-x64.AppImage
After installation:
- Launch PeerLLM Host.
- Enter your Machine ID (provided when you sign up as a Host).
- Connect to the Orchestrator network and start contributing compute power.
![]()
Download PeerLLM Host v0.7.6, connect your machine, and become part of the decentralized, ethical AI future.