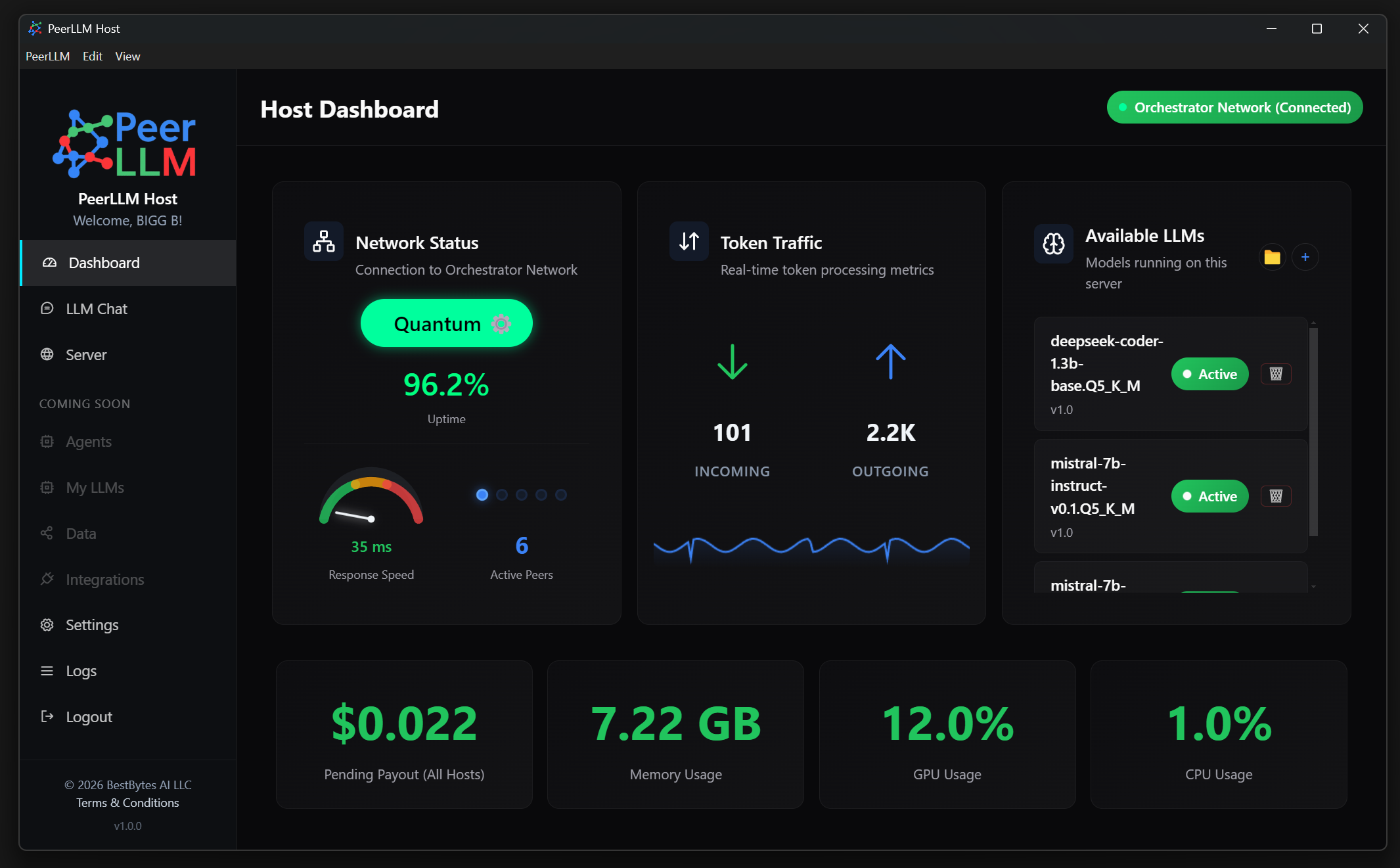
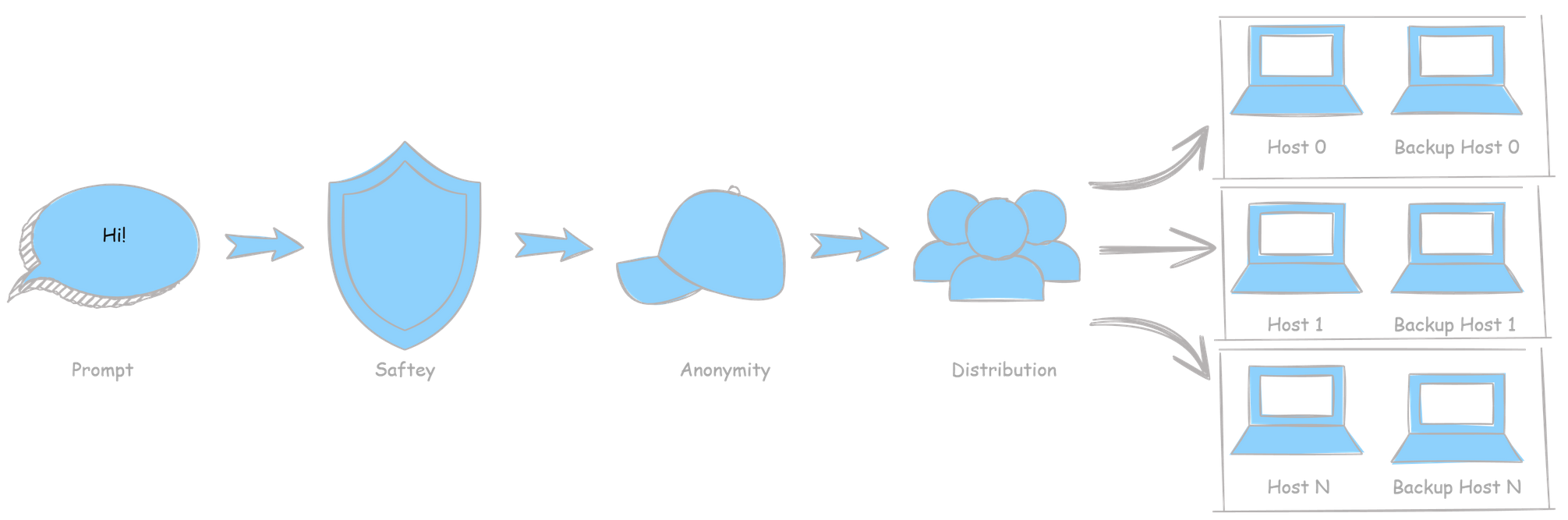
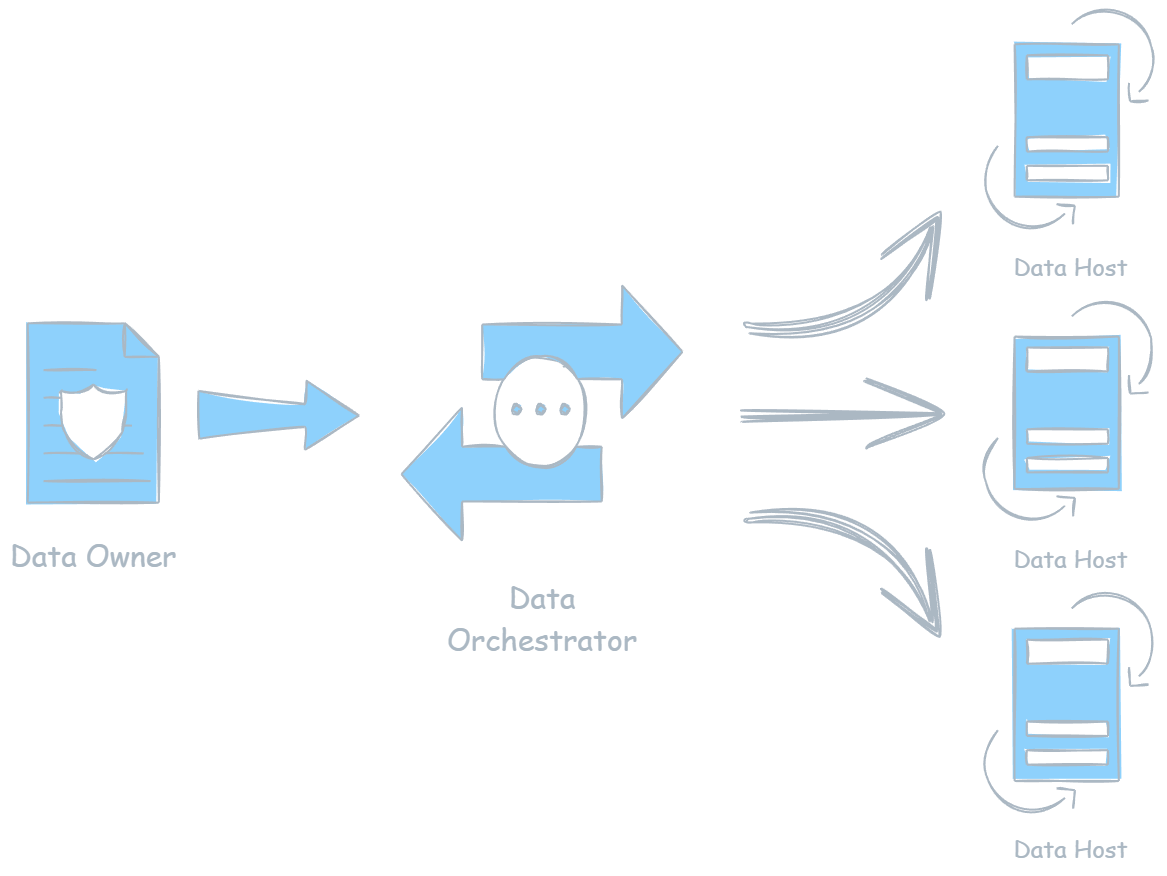
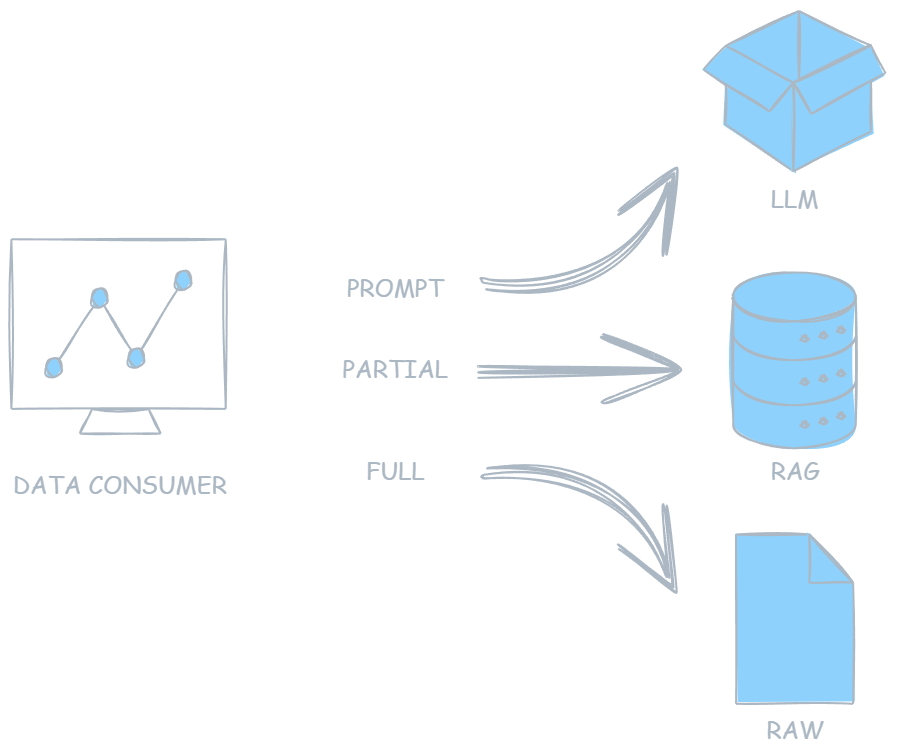
This release is focused on making your machine perform at its highest potential within the network.
The goal here is not to introduce surface-level features, but to ensure that when your host participates in PeerLLM, it does so in a way that is consistent, efficient, and aligned with the expectations of a distributed system. This means improving how your machine decides, how it allocates resources, and how it behaves under real load conditions.
1/ Finding the Best Configuration for Your Machine
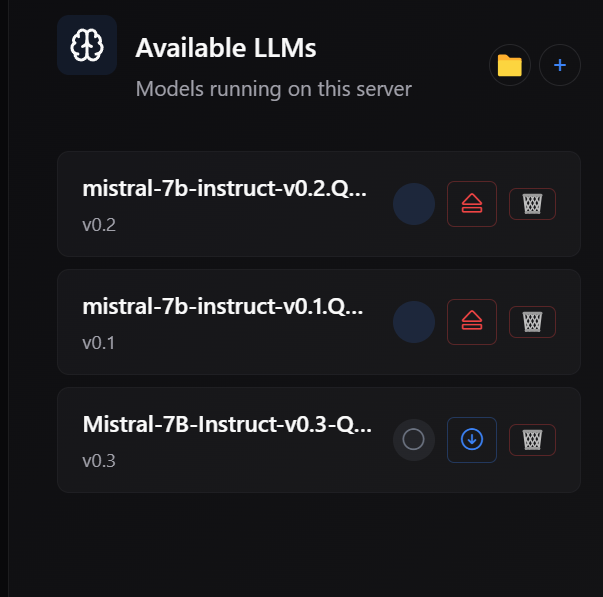
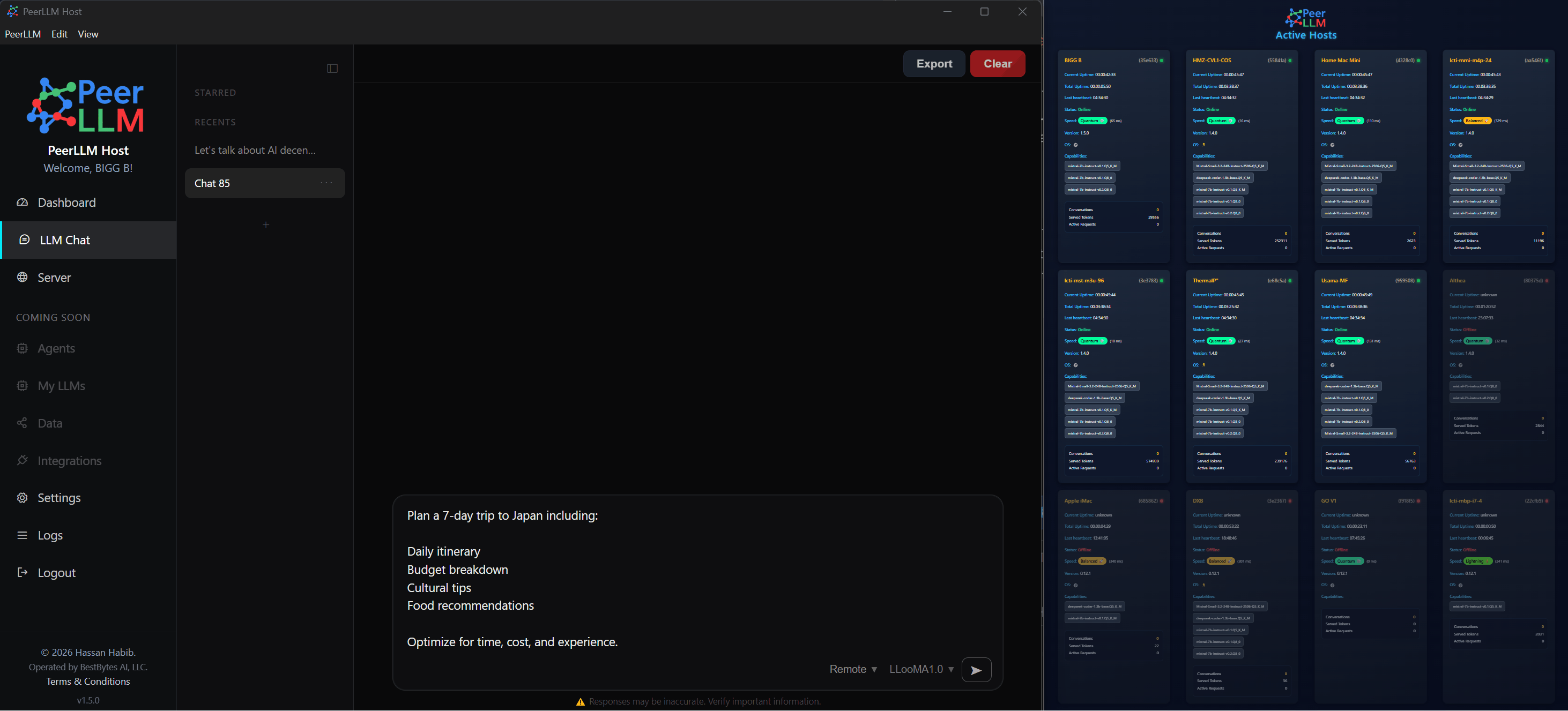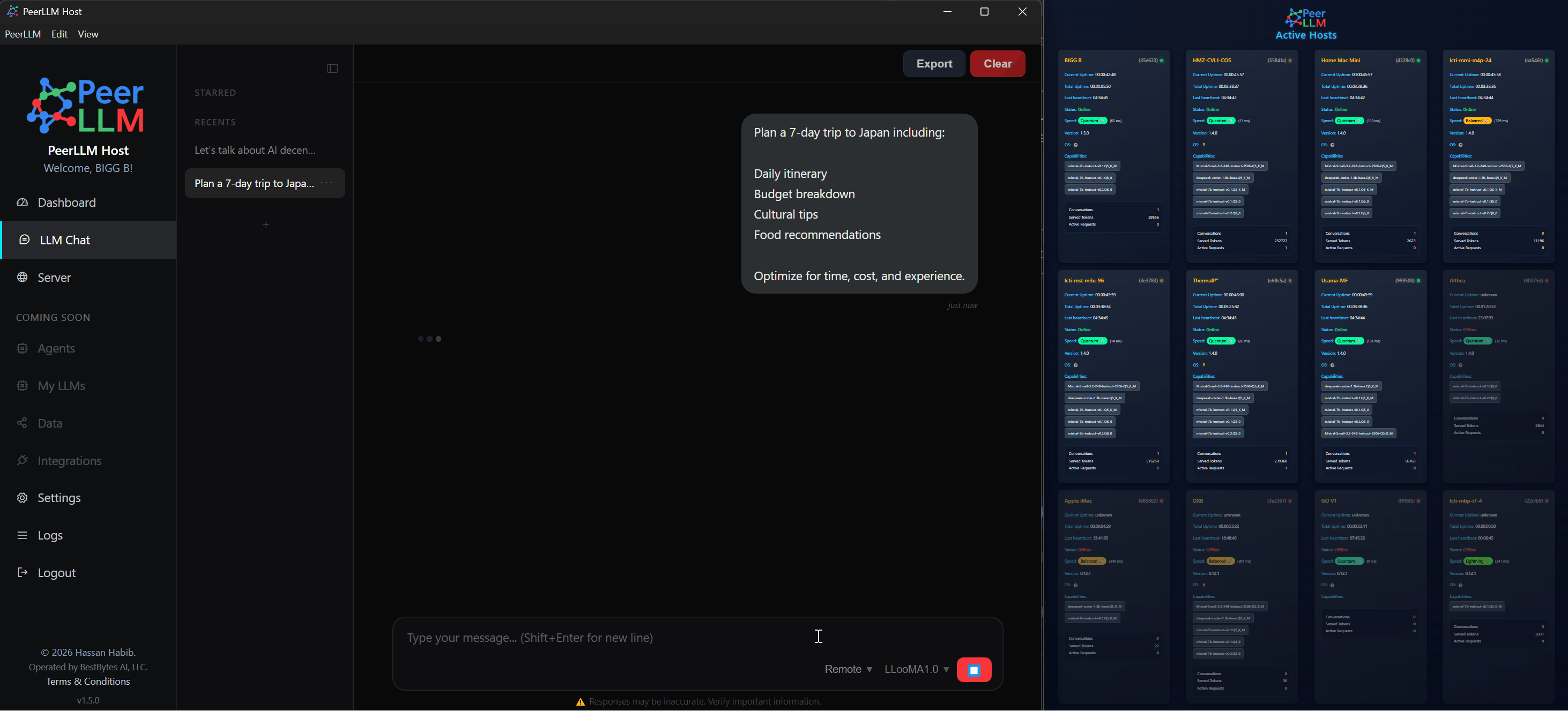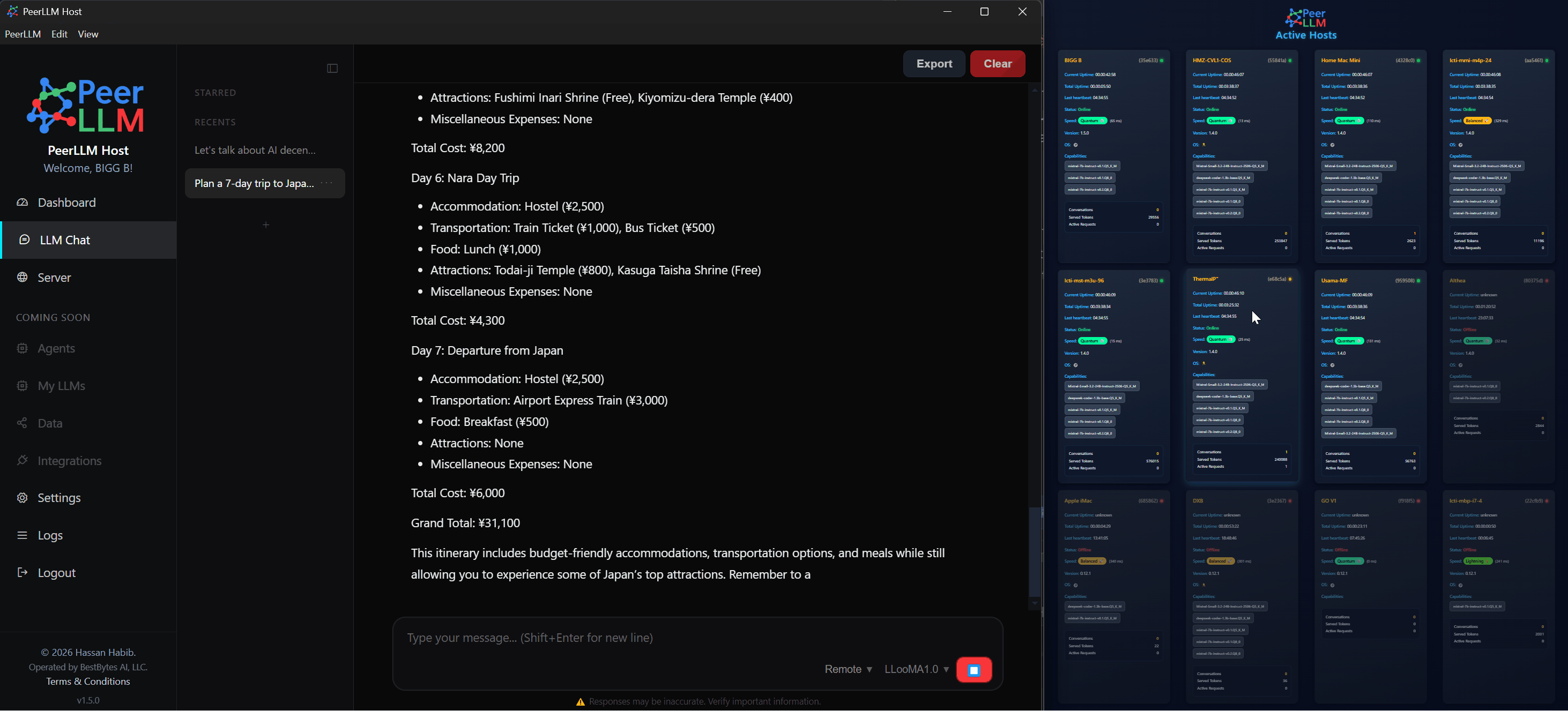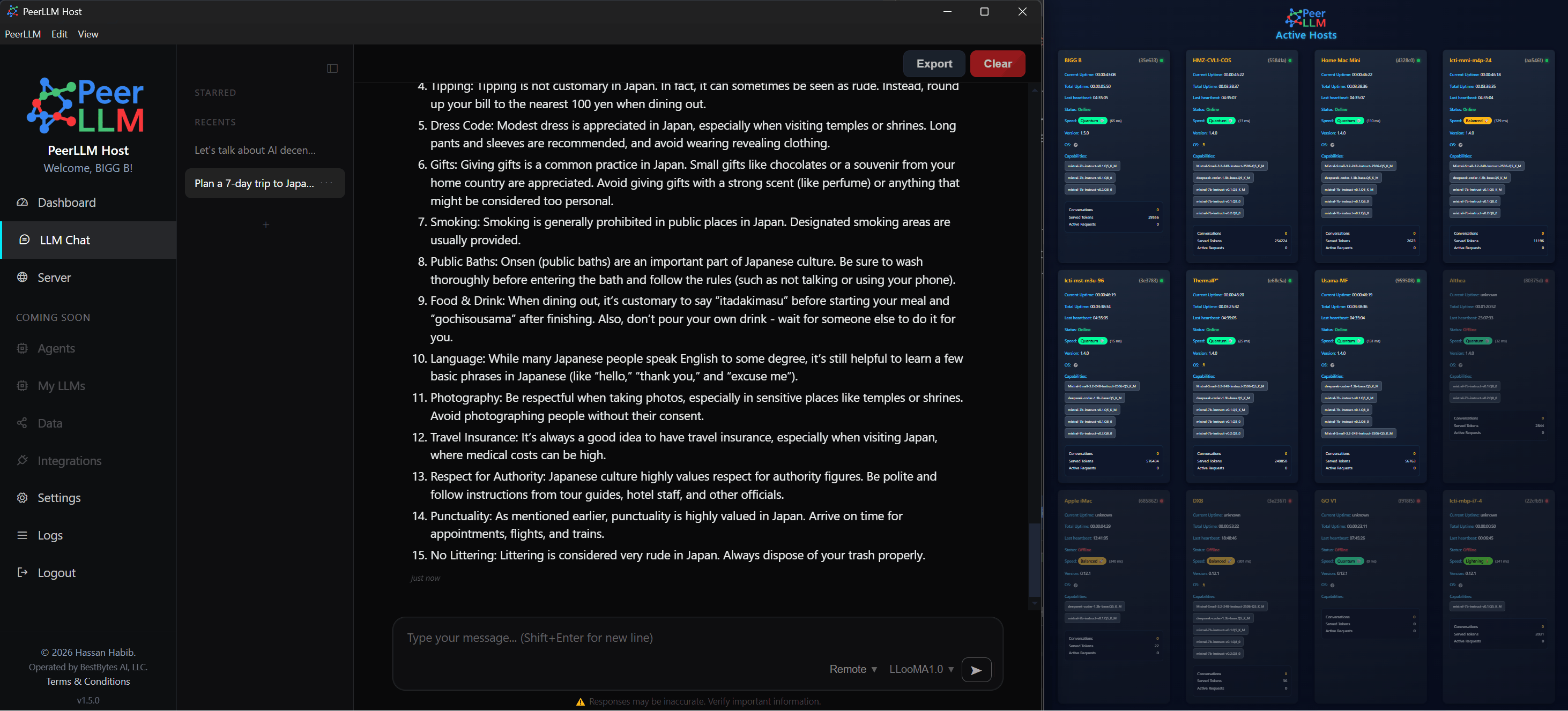
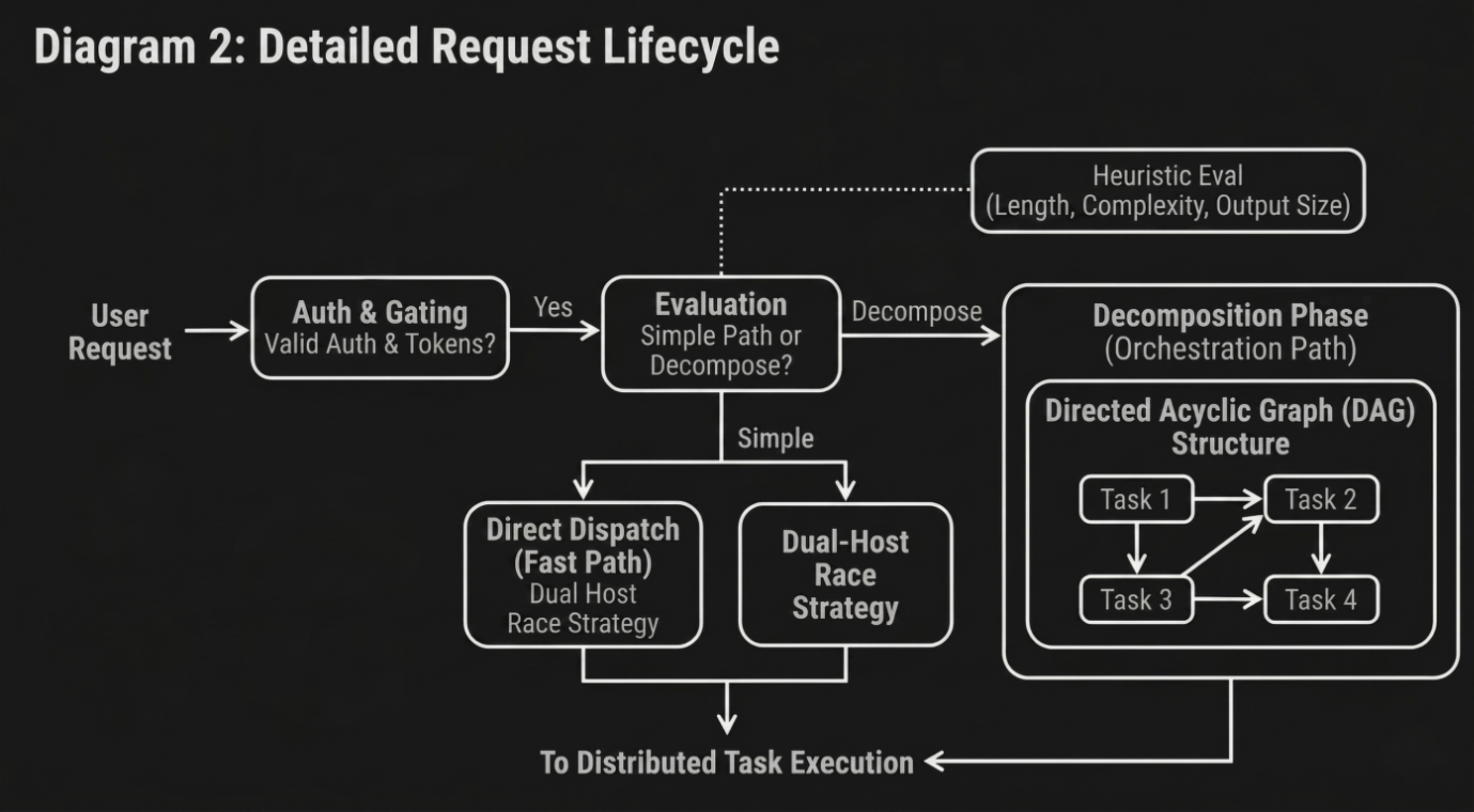
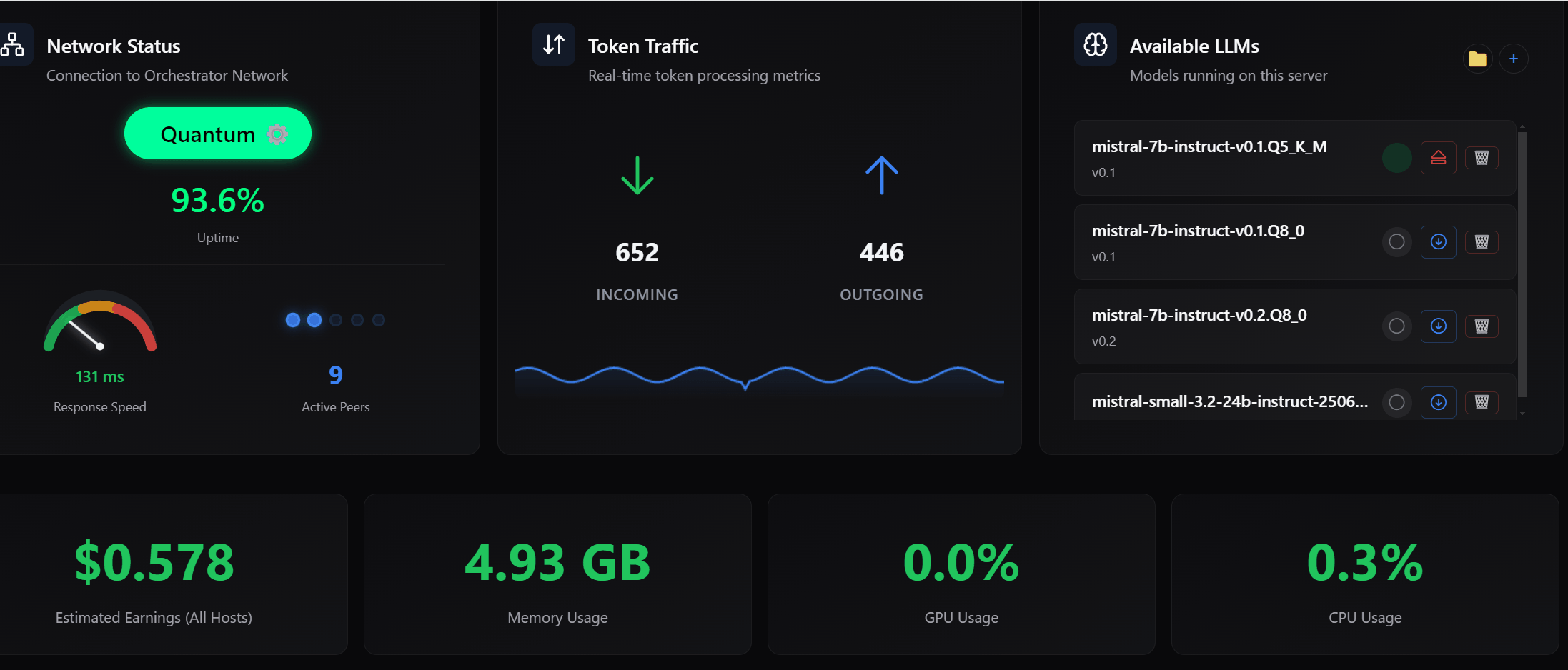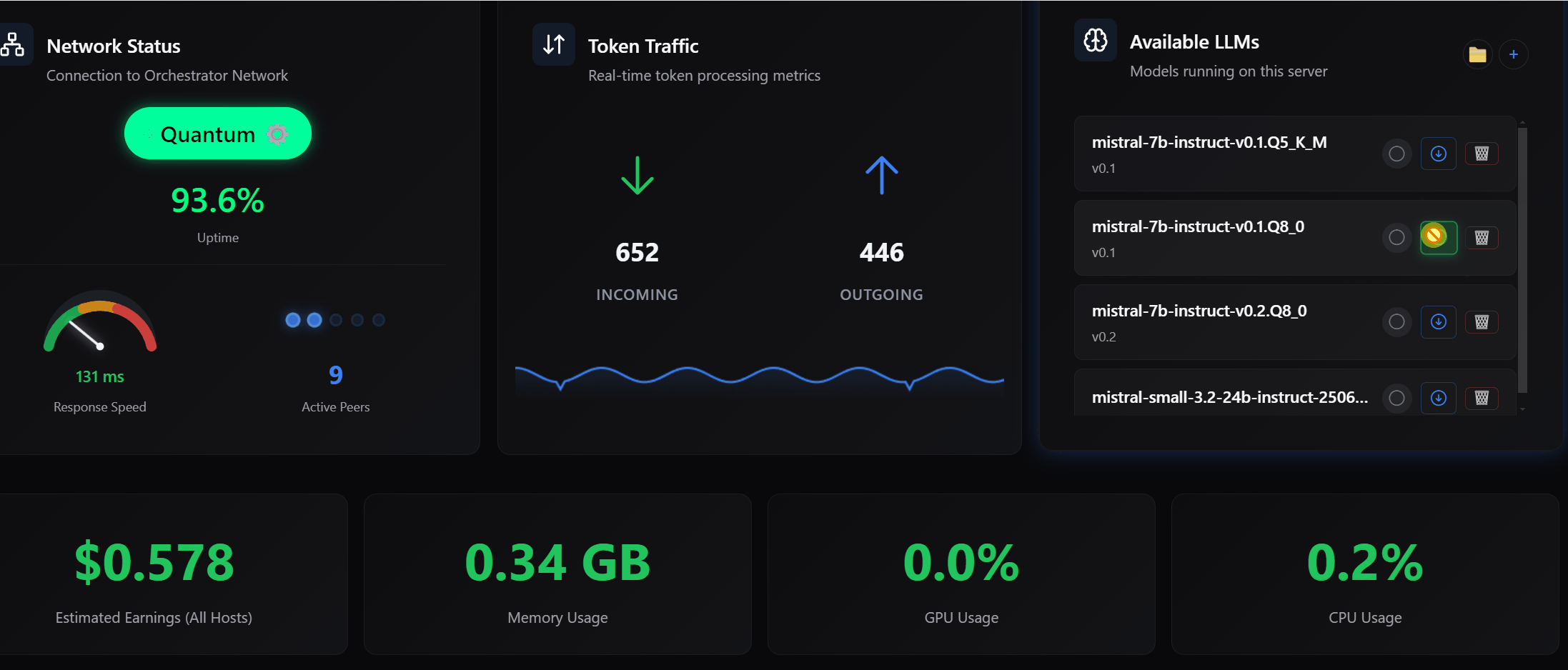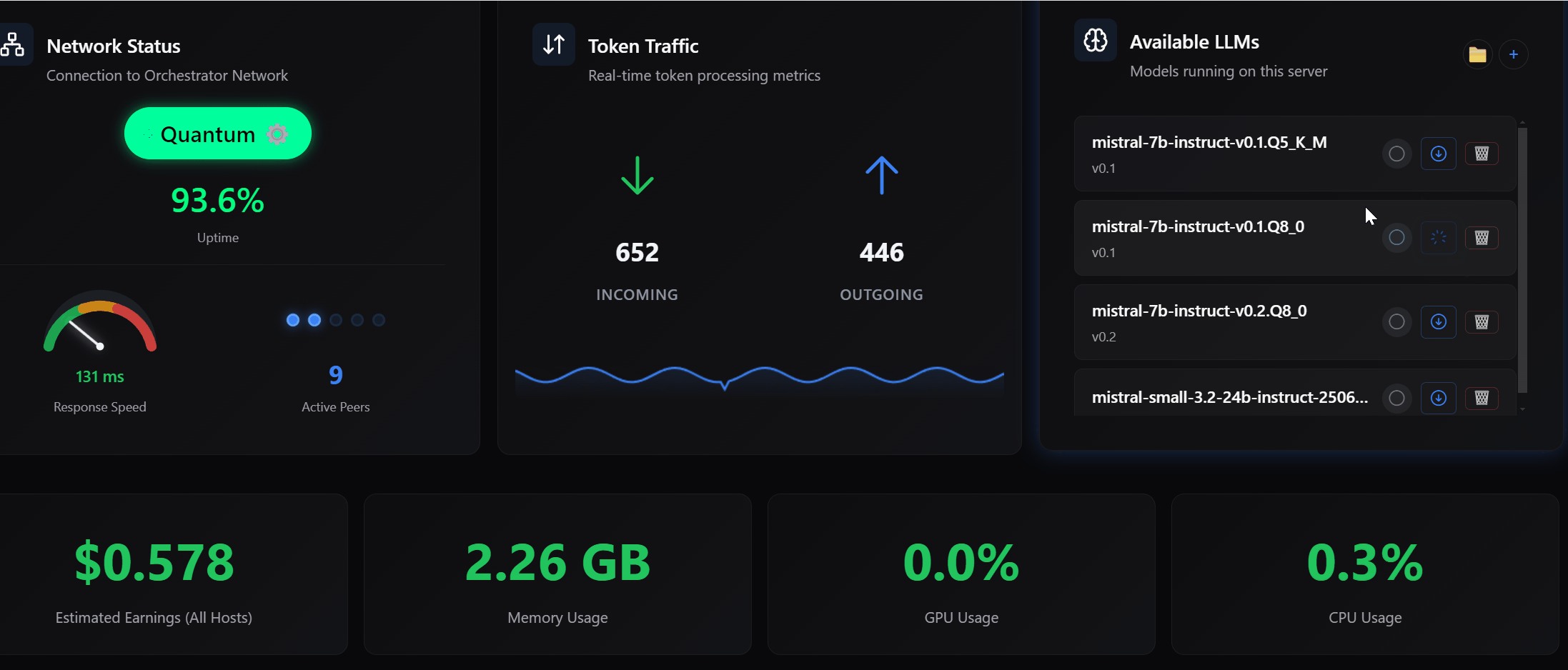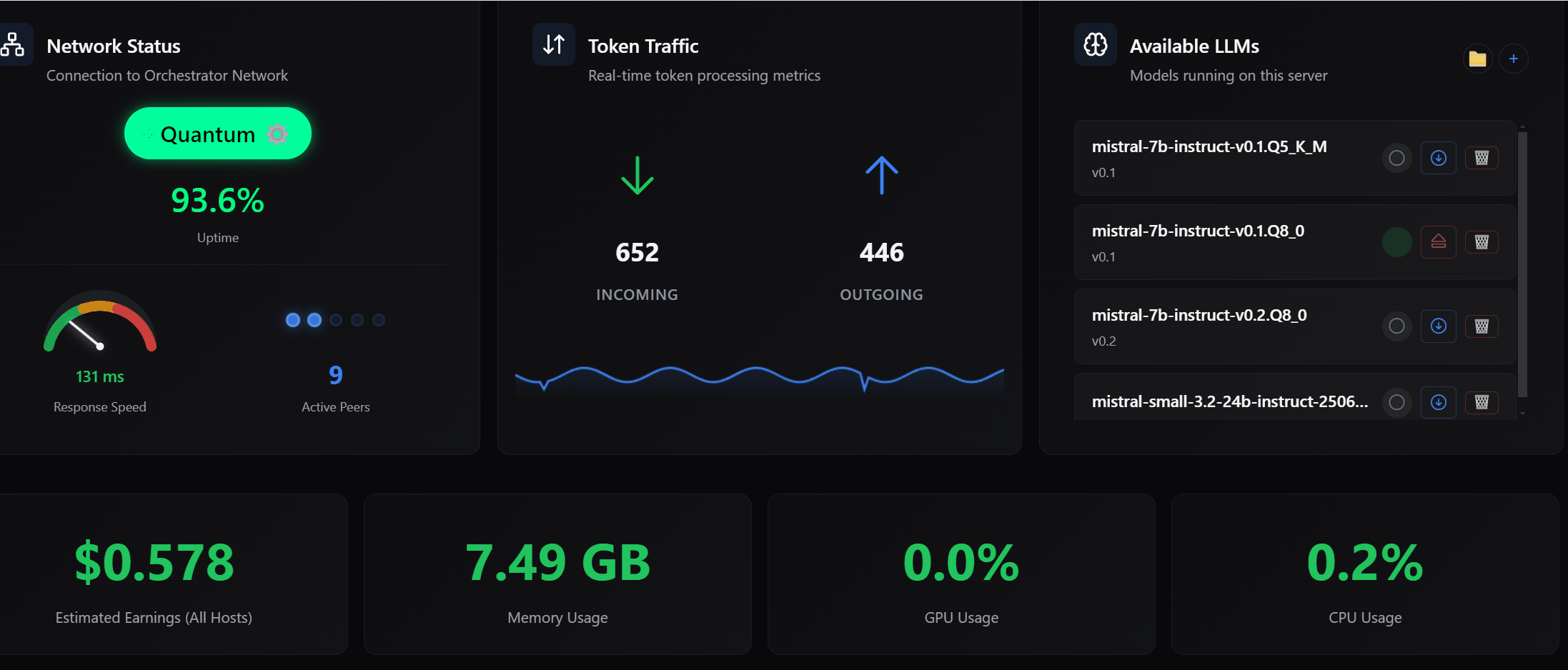
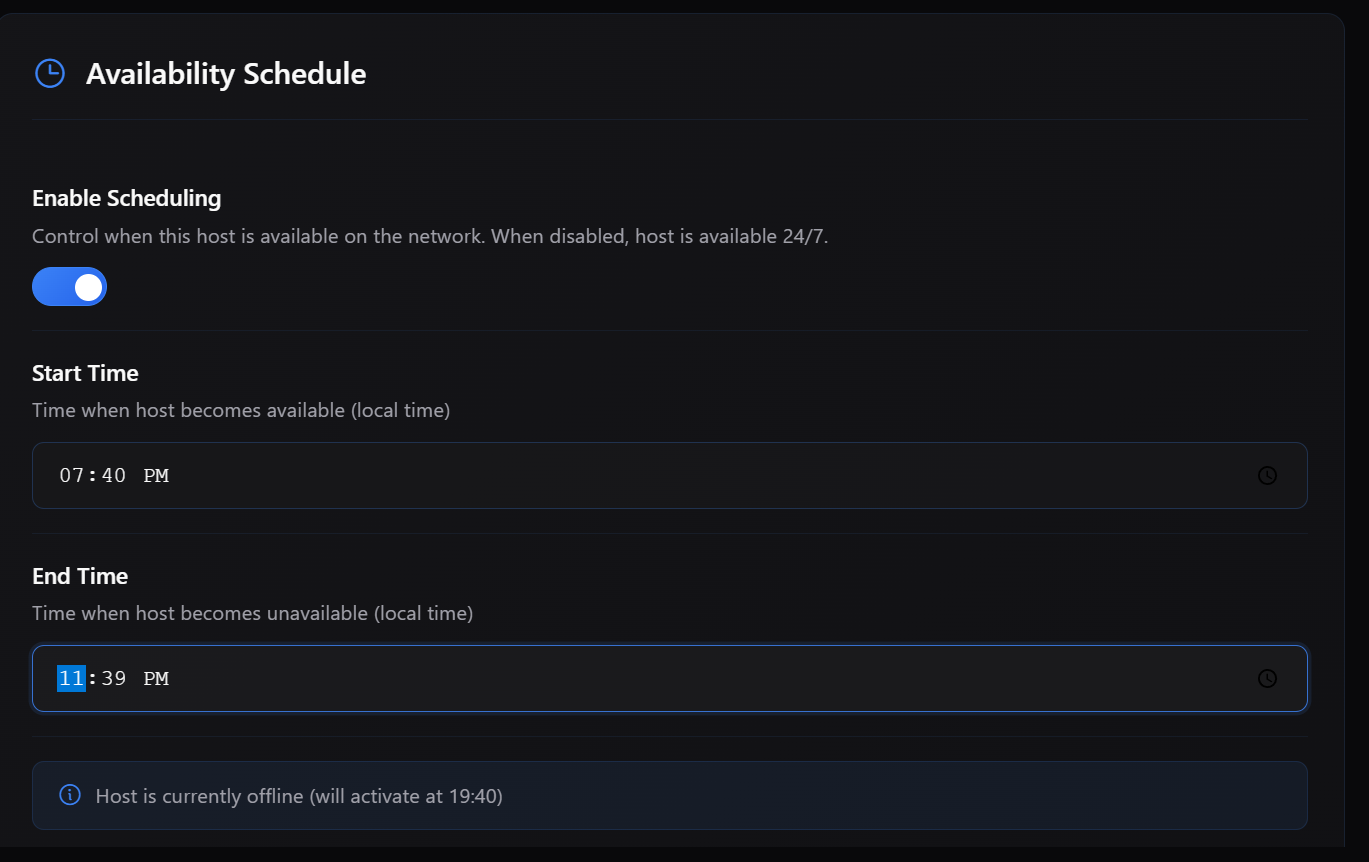
One of the most important additions in this release is the introduction of an Auto-Benchmark system that allows your machine to determine its optimal configuration based on actual performance rather than assumptions.
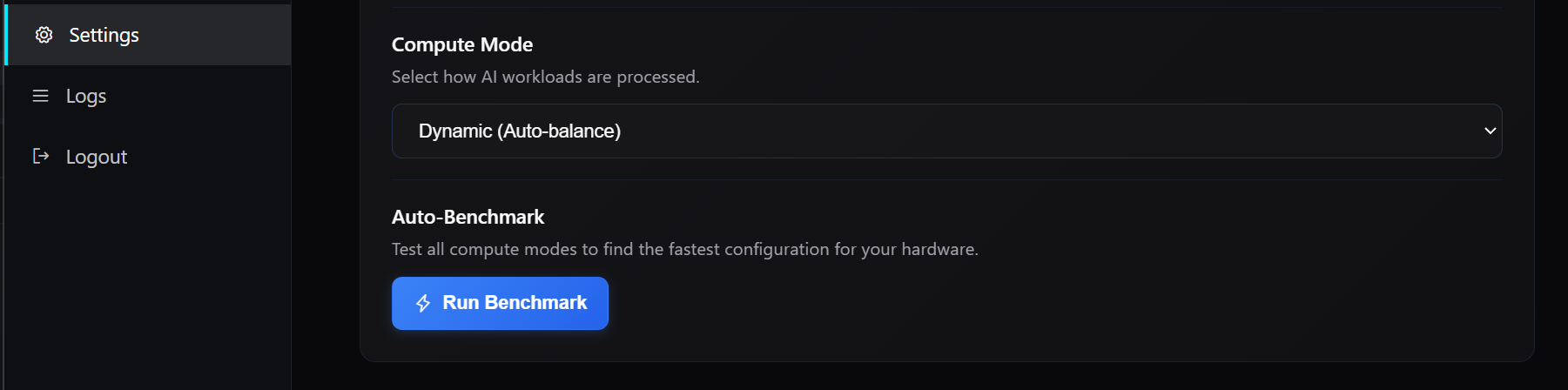
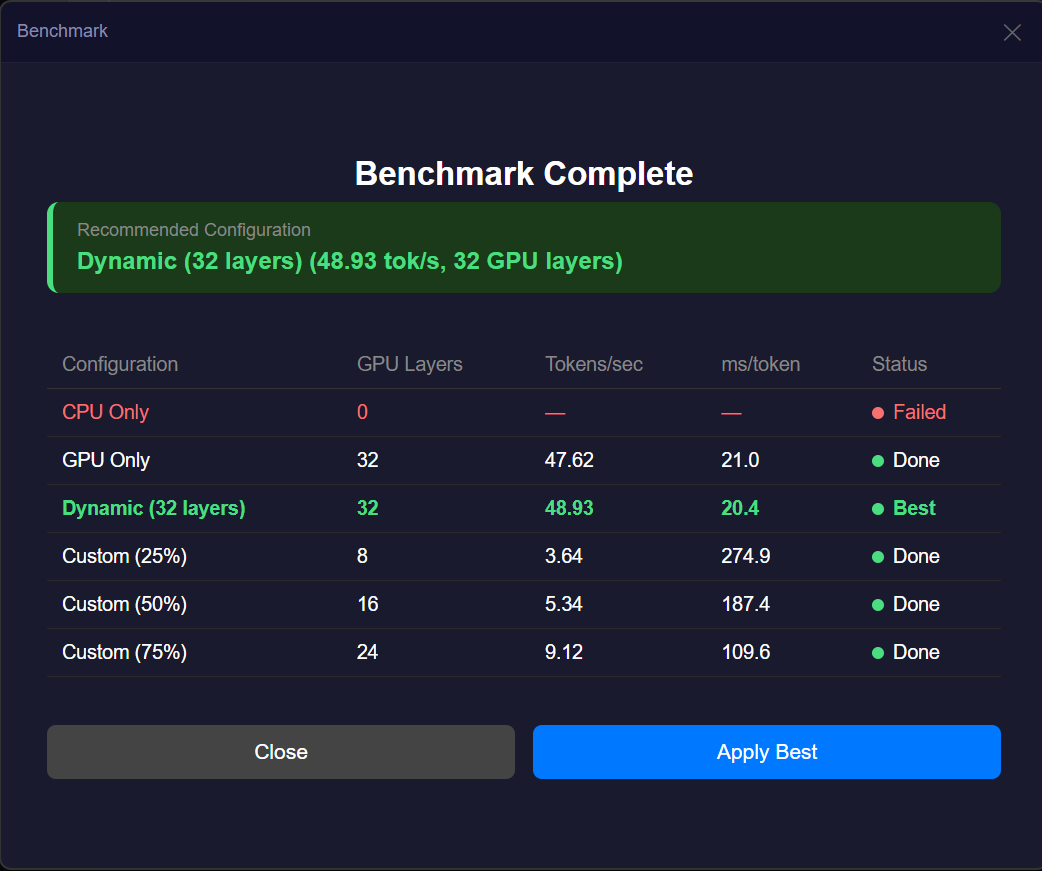
Different machines behave differently depending on their hardware, memory constraints, and compute modes. Instead of relying on static configurations, you can now run a benchmark that evaluates multiple compute modes, including CPU, GPU, dynamic allocation, and custom configurations. The system measures real tokens per second and recommends the configuration that delivers the best performance. Once identified, that configuration can be applied immediately.
This ensures that your host is not operating below its potential and that the network benefits from the most efficient version of your compute.
2/ Improving Memory Management and Sustained Throughput
A significant portion of this release is dedicated to improving how memory is managed across the system. Models now transition more cleanly between loaded, active, and idle states, which reduces stale memory usage and improves overall stability.
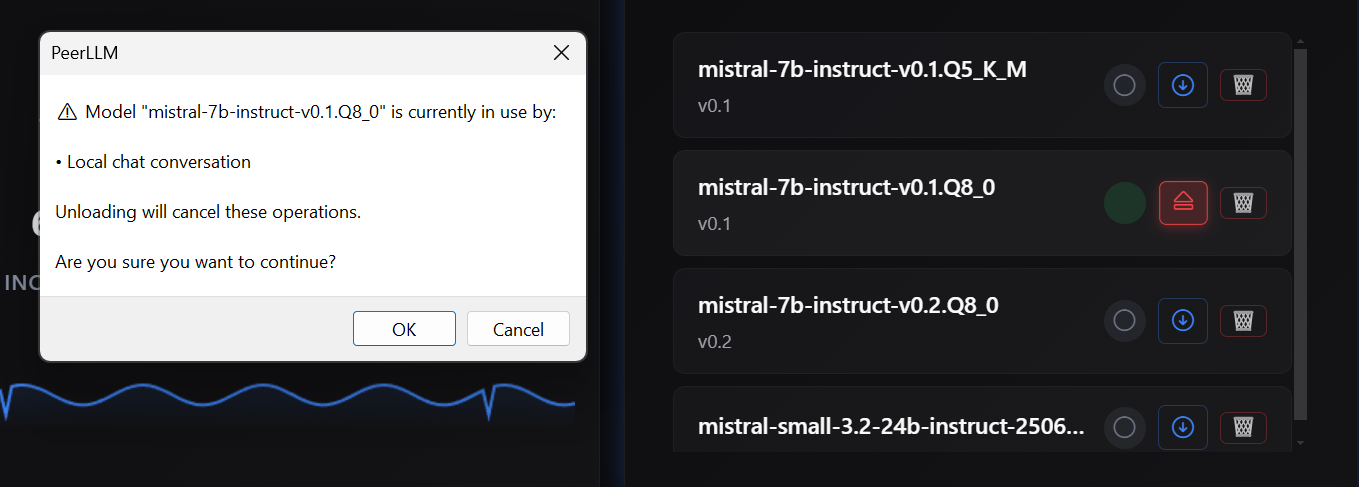
I also introduced mechanisms to validate capacity before execution begins, ensuring that your machine only accepts work it can realistically complete. When changes to memory allocation are required, such as unloading models to make room for new ones, the system now provides clear confirmation rather than making silent decisions.
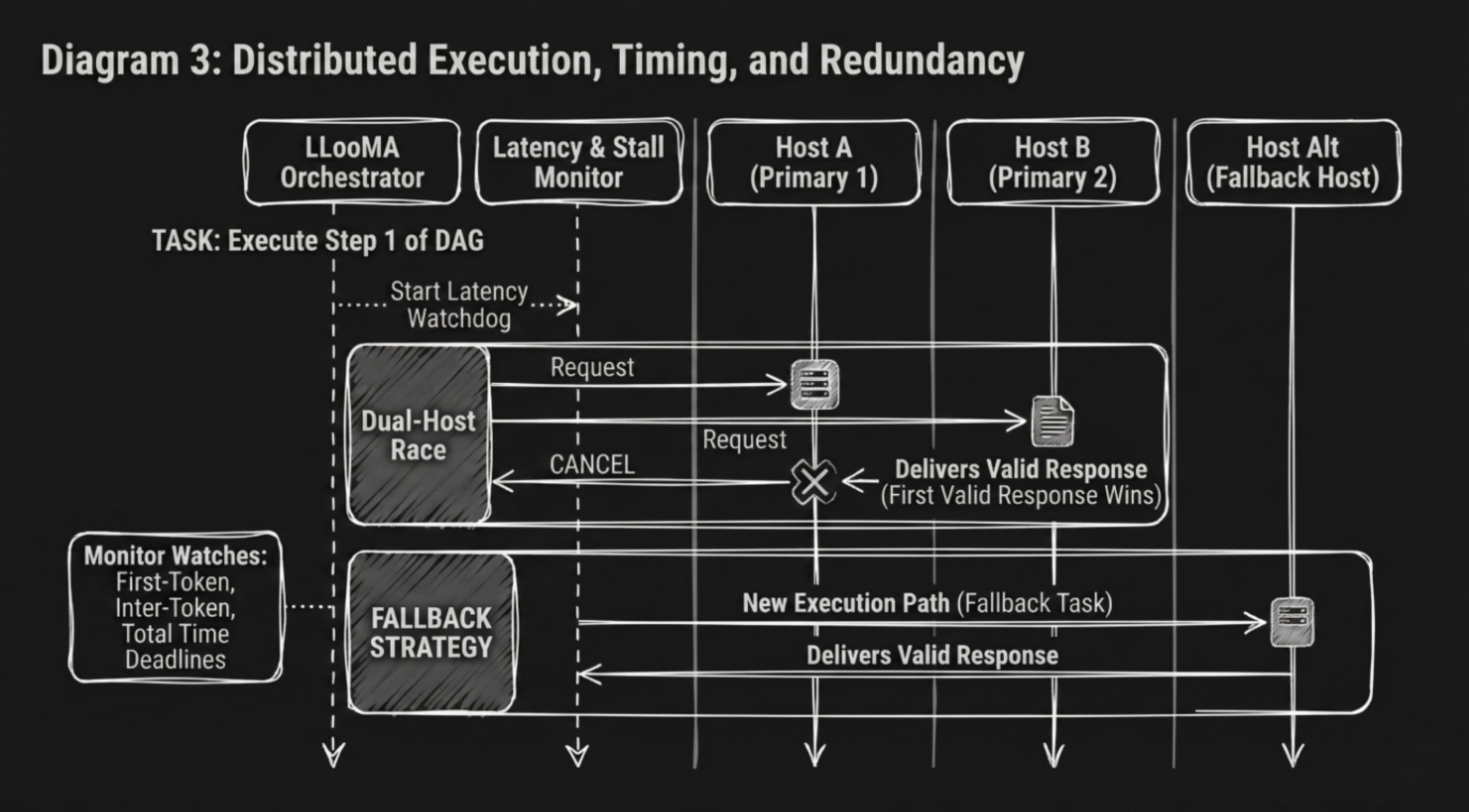
These changes result in more predictable execution, fewer interruptions, and better sustained throughput over time.
3/ Improving Resource Awareness
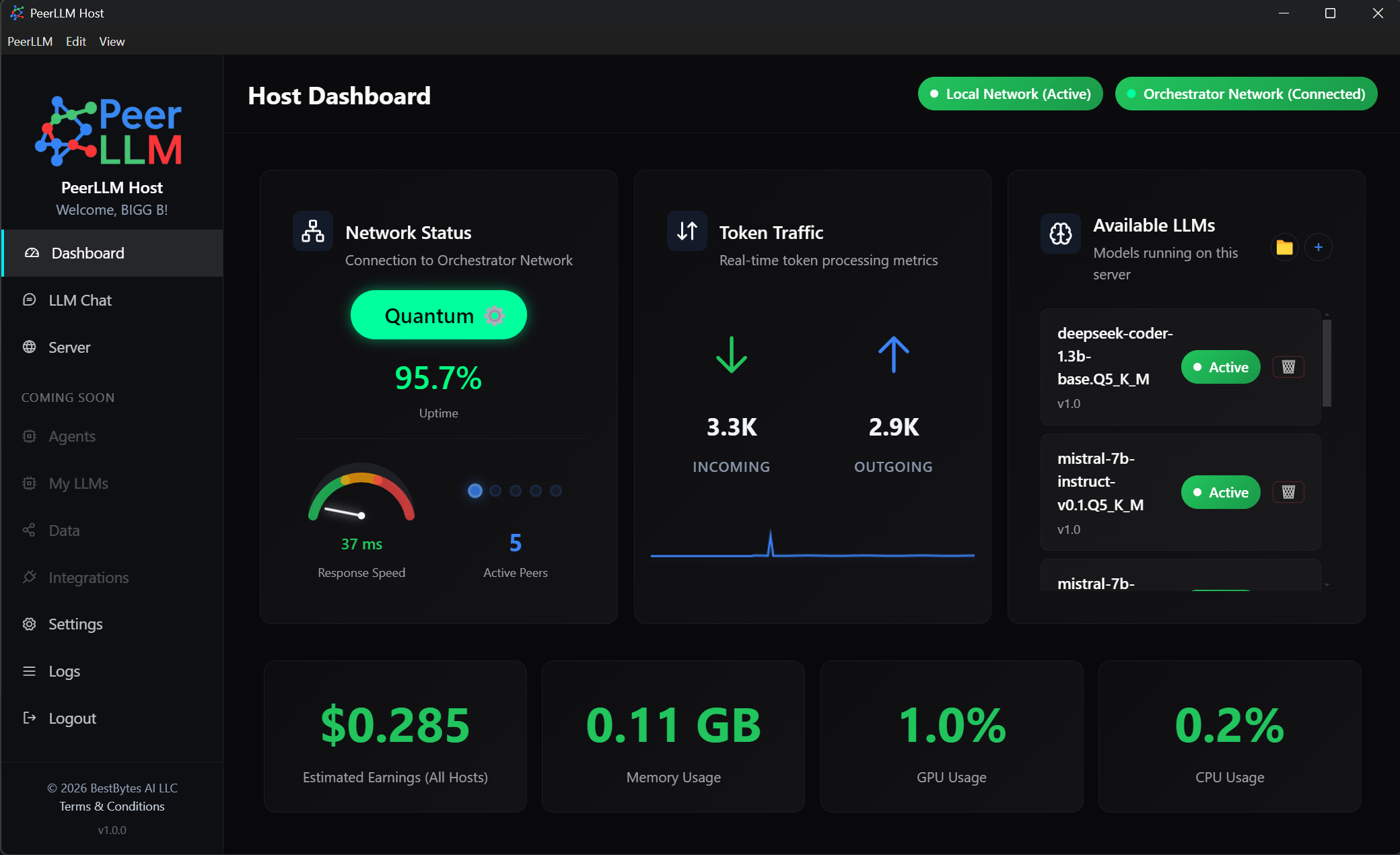
For a distributed system to function efficiently, it must have an accurate understanding of the resources available on each participating host. This release improves how your machine reports and interprets its own capabilities.
I enhanced GPU utilization detection across NVIDIA, AMD, and Intel environments, and ensured that the system respects your selected GPU in multi-GPU configurations. Additionally, memory calculations now reflect the actual compute mode being used rather than assuming a fixed allocation model.
These improvements allow the network to make better decisions when routing work, which directly impacts performance, latency, and overall reliability.
4/ Strengthening Execution Decisions
This release introduces a more disciplined approach to execution by evaluating whether a request should be accepted before it begins. By validating capacity and readiness ahead of time, the system avoids situations where work starts but cannot be completed.
When a host determines that it cannot fulfill a request, it now communicates this early, allowing the network to reroute the task to another host without delay. This reduces failed executions, improves response consistency, and strengthens the overall behavior of the network under load.
5/ Improving System Stability and Predictability
Beyond visible features, a large portion of the work in this release focuses on stabilizing the internal behavior of the system. This includes improvements to lifecycle management, background processes, and consistency in how the host operates over time.
While these changes are not directly visible, they play a critical role in ensuring that the system behaves predictably. Hosts remain more consistent in their operation, edge cases are reduced, and overall reliability improves in ways that compound over time.
6/ Improving Communication from the Network
Your host now has better visibility into how it is interacting with the network. This includes clearer communication about which models are accepted, how capabilities are interpreted, and when adjustments are made during the registration process.
This reduces ambiguity and allows you to operate your host with a better understanding of how it is being utilized within the network.
7/ Safer and More Controlled Defaults
I also made improvements to how the system behaves out of the box, focusing on safer defaults and more controlled interactions. This includes better handling of local services, improved boundaries around execution behavior, and stronger assumptions about how the system should operate in a shared environment.
These changes ensure that new hosts start from a more reliable baseline while still allowing advanced users to configure the system as needed.
8/ Closing
PeerLLM is not built on the idea that more features create a better system. It is built on the idea that better behavior creates a stronger network.
This release is a step in that direction. It ensures that each host contributes more effectively, that decisions are made with better information, and that execution across the network becomes more predictable and reliable.
As the network grows, these improvements become foundational. They are what allow PeerLLM to scale not just in size, but in quality.
You can download PeerLLM v1.7.1 here.
~ Hassan
]]>