LLooMA In Depth - A Network-Native Orchestration Architecture
LLooMA 1.0 (Low-Latency Orchestration of Models and Agents) is a network-native orchestration system that operates at a layer above traditional large language models. Unlike conventional models, LLooMA does not exist as a set of weights or a runtime artifact. It is not deployed on any host machine, nor is it executed as a standalone inference engine. Instead, LLooMA exists entirely within the PeerLLM orchestrator as a decision-making system responsible for coordinating how intelligence is applied across a decentralized network of independently operated hosts.
At its core, LLooMA transforms a single prompt into a distributed execution plan. Rather than treating a request as a monolithic unit of work, the system evaluates whether the request can benefit from decomposition, parallelism, or staged execution. This allows LLooMA to dynamically adapt its strategy based on the complexity and structure of the incoming request, providing a level of flexibility and efficiency that is not achievable through single-model inference.
0/ Architectural Positioning
From an architectural perspective, LLooMA occupies a unique position between traditional inference systems and distributed execution frameworks. It combines characteristics of both, while introducing a new abstraction layer that focuses on orchestration rather than computation.
The PeerLLM network provides the compute layer, consisting of heterogeneous hosts running local models with varying capabilities, performance characteristics, and availability. LLooMA operates as the control plane for this network. It is responsible for interpreting user intent, constructing execution plans, routing tasks, enforcing latency constraints, and aggregating results into a coherent output. This separation of concerns allows the system to scale compute independently from decision-making logic, enabling more sophisticated orchestration strategies over time.
1/ Request Lifecycle and Execution Model
Every request entering the system follows a structured lifecycle. The orchestrator first validates authentication and ensures sufficient token balance before any compute resources are allocated. This early gating mechanism prevents unnecessary load on the network and guarantees that all subsequent work is economically valid.
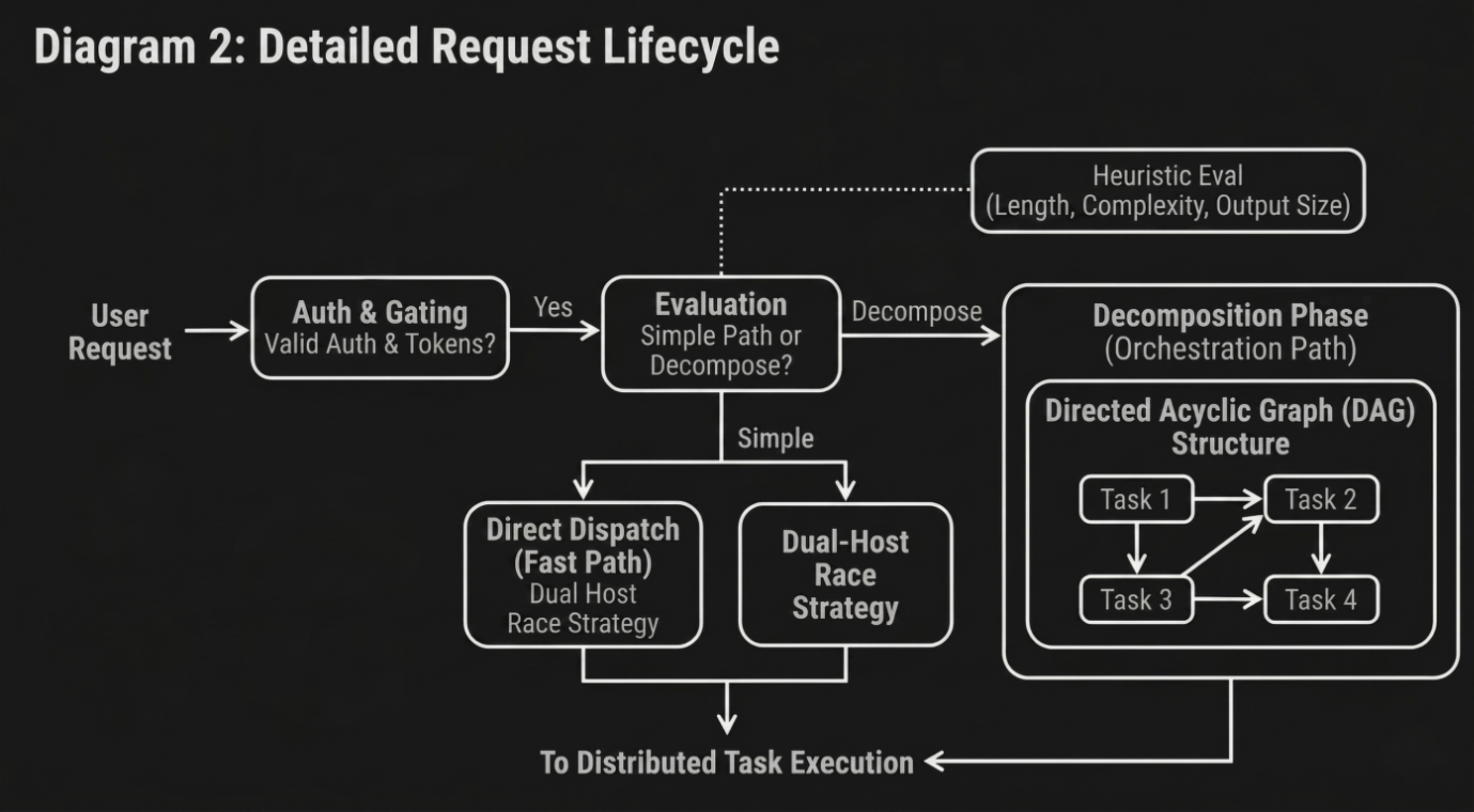
Once validated, LLooMA inspects the request to determine whether it should be processed as a single unit or decomposed into multiple tasks. This decision is based on heuristic evaluation of prompt length, structural complexity, and expected output size. Simple requests are routed through a fast path that bypasses orchestration and directly leverages the network through a dual-host race strategy. More complex requests proceed to the decomposition phase.
In the decomposition phase, the request is transformed into a directed acyclic graph (DAG) of tasks. Each node in the graph represents a self-contained unit of work, defined by its own prompt, dependencies, and execution constraints. The DAG structure allows LLooMA to identify parallelizable segments of the problem while preserving necessary execution order for dependent tasks. This model enables efficient utilization of network resources by executing independent tasks concurrently while coordinating dependent tasks in sequence.
2/ Distributed Task Execution
Task execution is performed across the PeerLLM host network. For each task, LLooMA selects eligible hosts based on liveness, capability, software version, and historical performance metrics. Rather than assigning a task to a single host, the system initiates a dual-host race. Multiple hosts receive the same task concurrently, and the first host to produce a valid response is selected as the winner. All other participating hosts are immediately cancelled.
Every request entering the system follows a structured lifecycle. The orchestrator first validates authentication and ensures sufficient token balance before any compute resources are allocated. This early gating mechanism prevents unnecessary load on the network and guarantees that all subsequent work is economically valid.
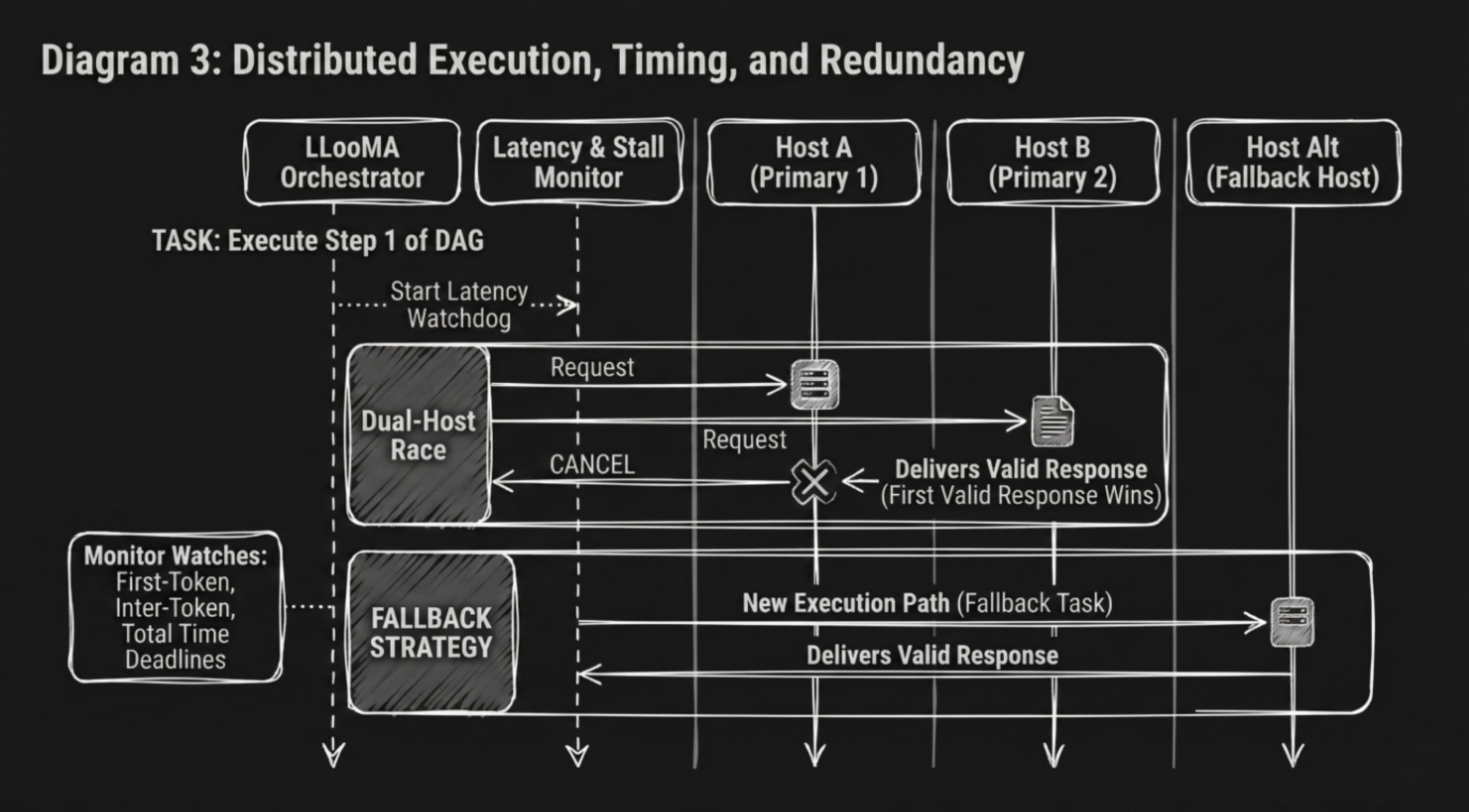
This race-based execution model significantly reduces latency and mitigates the impact of slow or unreliable hosts. It also introduces a natural form of redundancy without requiring explicit replication strategies. By favoring the fastest valid response, LLooMA ensures that the system consistently delivers low-latency results even in the presence of heterogeneous infrastructure.
3/ Latency Enforcement and Failure Handling
A key aspect of LLooMA’s architecture is its strict enforcement of latency budgets. Each task execution is governed by multiple timing constraints, including first-token deadlines, inter-token stall detection, and total response time limits. These constraints are continuously monitored throughout execution.
If a host fails to produce an initial response within the allowed time window, the system abandons the host and initiates a fallback strategy. Similarly, if a response stalls during streaming, LLooMA intervenes and continues the generation process through an alternative execution path. This ensures that no single host can degrade the user experience by introducing excessive latency or incomplete outputs.
Failure handling is designed to be seamless. Partial outputs are preserved and extended when possible, allowing the system to recover gracefully without restarting the entire computation. This approach minimizes wasted work and maintains continuity in the generated response.
4/ Response Normalization and Context Management
Given the diversity of models and environments within the network, responses can vary significantly in format and structure. LLooMA addresses this through a dedicated normalization layer that standardizes outputs before they are consumed by downstream tasks or returned to the client.
Normalization includes the removal of model-specific artifacts, whitespace correction, and structural formatting adjustments. This ensures that all outputs conform to a consistent representation, regardless of their source.
In addition to normalization, LLooMA implements context compression to manage token efficiency. When task outputs are used as inputs for subsequent tasks, they are compressed using deterministic heuristics that preserve essential information while reducing token count. This allows the system to maintain high throughput without incurring excessive token costs.
5/ Result Aggregation
Once all tasks in the DAG have completed, LLooMA aggregates their outputs into a final response. The aggregation process is guided by task-level merge strategies, which define how individual results should be combined. These strategies include simple concatenation, replacement, summarization, and custom synthesis.
Aggregation may be performed mechanically or through an additional intelligence layer, depending on the complexity of the task graph. The objective is to produce a single coherent response that abstracts away the underlying distributed execution. From the client’s perspective, the result appears as if it were generated by a single system, despite being the product of multiple coordinated computations.
6/ Scaling Characteristics
Traditional systems scale along two primary dimensions: vertical scaling, which increases the capacity of individual machines, and horizontal scaling, which increases the number of machines. LLooMA introduces a third dimension: intelligent scaling.
Intelligent scaling refers to the system’s ability to adapt its execution strategy based on the nature of the request. Simple requests incur minimal overhead and are processed directly, while complex requests trigger distributed execution across multiple hosts. This dynamic adjustment allows the system to allocate resources efficiently, scaling computational effort in proportion to problem complexity rather than uniformly across all requests.
7/ Reliability in a Decentralized Environment
Decentralized networks are inherently unpredictable. Hosts may join or leave at any time, performance characteristics may vary, and network conditions may fluctuate. LLooMA is designed to operate effectively within this environment by assuming that failure is the norm rather than the exception.
The combination of host racing, latency enforcement, fallback strategies, and continuous monitoring creates a resilient system that maintains consistent performance despite underlying instability. By decoupling execution from any single host and continuously adapting to network conditions, LLooMA achieves a level of reliability that would be difficult to attain in a purely centralized or purely decentralized system.
8/ Conclusion
LLooMA represents a shift in how intelligence systems are designed and deployed. Rather than focusing on improving individual models, it introduces an orchestration layer that determines how multiple models and machines collaborate to solve a problem.
This approach enables a more flexible, scalable, and resilient system, where intelligence is not confined to a single model but distributed across a network. As the PeerLLM network grows, LLooMA’s ability to coordinate and optimize execution will continue to improve, further enhancing the capabilities of the system.
In this architecture, intelligence is no longer a static artifact. It becomes a dynamic process, shaped by the interaction between decision-making logic and distributed compute resources.
👉 Download the full whitepaper:
LLooMA Whitepaper v1.0.0 (PDF)
Hassan