LLooMA 2.0: Teaching a Community of Hosts to Call Tools
A month ago, I ended a post with a promise: tools would not stay at the center. Hosts would advertise the tools they can run, the same way they advertise the models they host, and the network would race for the work.
This post is how I kept it, and the engineering it took to make tool-calling reliable across a community of machines I do not own, running models I did not choose.
LLooMA 2.0 is agentic. It speaks the standard tool-calling API on /v1, the same one your agent already uses, and the tool decisions are made by community hosts. Here is the hard part nobody warns you about, and how I solved it.
Two Rules That Come First
Everything below is in service of two principles that do not bend.
Decentralization first. LLooMA always tries the people’s network before anything else. A real prompt is served by community hosts running on volunteers’ machines, and only when no community host can do the job does the work fall back to PeerLLM’s own dedicated core. The decentralized path is the default. PeerLLM’s core is the exception, never the starting point.
Privacy by fragmentation. LLooMA spreads work across many independent hosts, and it never hands any of them your identity. A host runs the task it is given and sees only what that task needs to run; it does not know who you are. For an agentic turn, the host that makes a tool decision does see the running conversation, but never the person behind it, and pushing that boundary further, so each host sees even less, is exactly where this is heading. The orchestrator is the only component that ever holds the whole picture, it holds it for only the instant it takes to route the work, and every hop travels over encrypted transport.
No single host can hold your identity, your intent, and your data at the same time. That is not a policy I promise. It is the shape of the system.

0/ Why This Is Hard
Tool-calling is, at bottom, a structured output problem. The model must emit a tool call as machine-parseable JSON, with the right tool name and arguments that match the tool’s schema, every single time. One stray token and the call is garbage.
A frontier model behind a corporate API does this well because it was trained and constrained to. LLooMA doesn’t have that luxury. LLooMA runs on a community of volunteers’ computers, and those computers run whatever model the volunteer downloaded: a 7B here, a 14B there, Qwen, Llama, Mistral, all different quantizations.
So the problem is:
Make a diverse community of models emit perfectly-valid tool calls, or fail in a way that never reaches the user.
The answer turned out to be three ideas stacked together: constrain the output, gate by capability, and degrade gracefully at every layer.
1/ The Loop: Resolve on the Server, Yield to the Client
The orchestrator runs a bounded agentic loop. Each iteration produces either a final answer or one or more tool calls. I split tool calls into two kinds and treat them very differently:
- Server-side tools (like
peerllm.web_search) the orchestrator executes internally, appends the result to the conversation, and loops again. The user never sees the round trip. - Client-side tools (your editor’s
read_file,run_command) the orchestrator yields back to the caller withfinish_reason: "tool_calls", because only the client can run them.
Loop-on-server, yield-on-client. That single distinction is what lets the same endpoint power both a “search the web and answer” turn and a full coding-agent session in your editor.
Every tool call, from any source, is validated against its JSON schema before it’s trusted. An unknown tool name or bad arguments isn’t an error to the user. It’s fed back into the conversation as a tool result so the model can self-correct on the next iteration:
Error: invalid arguments for 'web_search': missing required 'query'. Please correct and retry.
2/ The Core Trick: Compile the Schema into a Grammar
Here’s the heart of it. I do not ask a community model to please return valid JSON and hope. I make invalid output impossible to generate.
llama.cpp supports GBNF, a grammar that constrains token sampling so the model can only produce strings the grammar allows. So I wrote a compiler that turns a tool catalog’s JSON schemas into a GBNF grammar at request time. The grammar permits exactly one of two shapes:
{ "name": "<one of the real tool names>", "arguments": <object matching that tool's schema> }
{ "answer": "<free text>" }
That second alternative matters: a grammar-constrained host can still decline to call a tool and just answer.
The compiler turns each tool’s schema into grammar rules, and the real tool names become the only names the model is allowed to produce, so it cannot invent a tool that doesn’t exist. Anything unusual in a schema relaxes to plain JSON, so the grammar always stays valid and a separate validator checks the finer details afterward.
The orchestrator builds this grammar per request, ships it to the chosen host, and the host hands it straight to its local engine. The result: syntactically-valid tool calls by construction, out of a model I’ve never tested. And if anything goes wrong building or applying the grammar, the host simply generates normally, the orchestrator validates, and it falls back. Nothing breaks.
Don’t coax structure with a prompt and pray. Make the invalid token unreachable.
3/ The Capability Gate: Advertising Is Not Competence
When I first shipped this, I learned something the hard way.
A host advertising that it supports tools is necessary but not sufficient. Not every model is reliable at tool-calling. Some will happily emit tool-call-shaped JSON and then invent the arguments: a file path that does not exist, a parameter nobody asked for. The grammar makes the shape valid; it cannot make the content correct.
So the host selector has a second gate. I route an agentic decision only to a host running a model with a proven tool-calling track record. A host without one is simply skipped, and PeerLLM’s core covers that turn instead. Among eligible hosts the work spreads evenly across the community, rather than piling onto whichever one the loop happens to see first.
4/ Decentralization First: Community Hosts, Then Core
This is where the first rule becomes machinery. The community path is always tried first, and PeerLLM’s own core is only ever the fallback. Read the host-emission path as a sequence of trapdoors, every one of which drops cleanly back to the core decider, but only after the community has had its shot:
- No grammar to compile? Core.
- No eligible strong-model host, or all at capacity? Core.
- Host doesn’t answer in time? Core.
- Output isn’t valid JSON, or isn’t one of the two grammar shapes? Core.
- Arguments fail schema validation? Core.
- Host emitter throws anything at all? Core.
A user-facing tool turn can fail for half a dozen reasons on a community host’s machine and still produce a correct answer, because PeerLLM’s core quietly does the decision itself. The decentralized path is pure upside: when it works, the community did the work and earns the estimated rewards for it; when it doesn’t, you never notice. People first, core as the safety net, never the other way around.
Distribute the work optimistically. Keep a deterministic fallback under every step, but never reach for it first.
5/ Loops That Can’t Run Away
Agentic loops have a famous failure mode: the model gets stuck calling the same broken tool over and over. I bound it twice.
Within a single request, a hard cap stops the tool rounds from running away. The subtler problem lives across requests: agentic coding clients re-send the whole conversation each round, so a model that keeps re-trying the same doomed call (say, reading a file that does not exist) could loop forever, because every request looks brand new to the server.
So before handing a tool call back to the client, the loop checks the conversation’s own history: has this exact call already failed more than once? If so, it stops re-trying and returns an honest message instead:
I couldn’t complete this request: the
read_filecall kept failing (no such file). Please check the path and try again.
Small but important: the check looks for genuine failure signals, not just the word “error,” so a file whose contents happen to mention errors is never mistaken for a failed call.
6/ Reward the Host That Did the Work
Decentralization without fair accounting is just outsourcing. When a host serves an agentic decision, it is credited estimated rewards for that turn, computed from the tokens it processed, exactly like a normal inference turn. (Rewards are estimates that depend on demand and network conditions, and can change.) The core fallback earns nothing, because no community host did the work.
And every response carries an X-LLooMA-Decider header naming who decided: a community host:<id>, or PeerLLM’s centralized core. No black box. You can see, per request, whether the people’s network or the core answered you.
Running agentic traffic is also a host owner’s choice. Every host has an operator on/off switch for it. Flip on Accept Agentic Requests in Settings to serve tool-calling traffic; leave it off to stay chat-only. Either way, in-progress requests always finish.
7/ Where It Stands
This is live today. Hosts are on v2.1.4, and on a recent production day in mid-June 2026, roughly seven of every eight agentic turns were decided by community hosts rather than PeerLLM’s core. The grammar holds. The gate holds. The fallback catches what’s left.
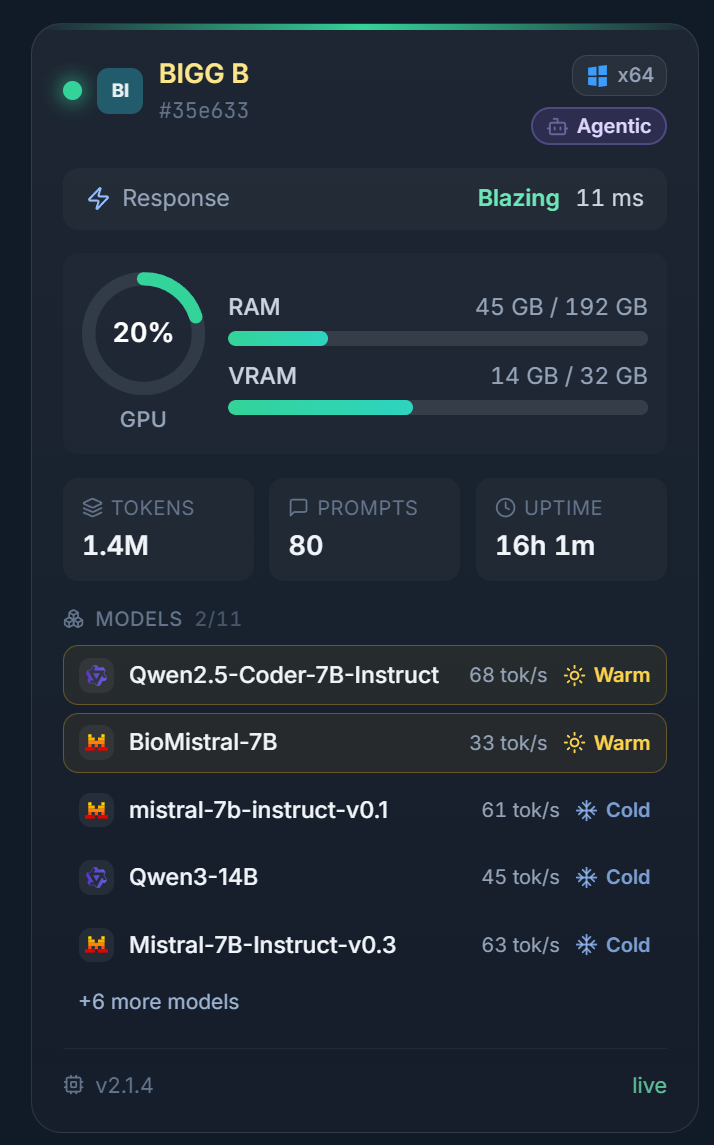
An agent-enabled host wears its capability openly on the network: the Agentic badge, its hardware, its resident models, and its live speed, all visible to anyone watching.
See it in action
Want to watch it work? Here I point VS Code’s Continue extension at LLooMA 2.0’s /v1 endpoint and have it write a small JavaScript program live, tool calls and all, served by the community network:
The pattern generalizes. web_search was the first network tool; code execution and document tools ride the exact same rails: compile a grammar, gate by capability, race a host, validate, fall back, reward. Every new capability is now a small, well-defended addition rather than a new architecture.
A month ago LLooMA could answer. Now it can act, and it does the acting the only way that’s honest across a community of independent hosts: constrain it, verify it, split it so no host sees the whole, hand it to the community first, and keep a deterministic safety net under every step.
I said hosts would race for tools.
Now they do.
A Heartfelt Thank You
A network is people. LLooMA 2.0 exists because a community of hosts keeps showing up: running real hardware, sending real feedback, and caring about this project like it is their own.
A special, heartfelt thank you to Phil Sager (@lactoseintolrnt on Discord), who has done the heavy, unglamorous work that makes everything above possible. Relentless testing. Sharp feedback. Dedicated hardware on the network. The willingness to push back on my ideas and bring a perspective I did not have.
Phil has been there for the good, the bad, and the ugly moments of testing, and never once stopped pushing with me even when the whole system seemed completely broken. And it does break, often. There is no manual for this. You cannot just Google how to decentralize LLMs. We are figuring it out as we go, and having someone in the trenches who keeps showing up through the broken builds means more than I can say. Phil, I could not be more grateful for people like you.
And deep thanks to the many others who shape this thing every single day. Christo, Paul, Usama, Hamza, and so many more who share daily insights and keep me balanced across LLMs, across networks, across operating systems. You bring me back to center more often than you know.
A single brain made of many minds. It turns out that is just as true of the people building it as of the network they run.
I could not be more grateful.
If you run a host, update to v2.1.4 and flip on the agentic toggle to start serving tool turns and earning estimated rewards alongside inference. If you build with the API, point your agent at LLooMA’s /v1 and watch the X-LLooMA-Decider header. That’s the community, working.
Estimated rewards depend on demand, uptime, and network conditions, can change at any time, and are not guaranteed. PeerLLM is experimental software provided as is. Product and model names referenced here belong to their respective owners and are mentioned only to describe interoperability; their mention does not imply affiliation or endorsement.
Hassan