PeerLLM v1.4.0 - Faster Hosts, Smarter Control, Real Momentum
PeerLLM v1.4.0 - Faster Hosts, Smarter Control, Real Momentum
PeerLLM v1.4.0 is about one thing.
Giving Hosts more control over performance, availability, and their machine.
This release focuses on real-world behavior.
- Faster responses
- Better memory management
- More predictable host control
Most importantly, it respects the Host’s environment.
0/ Pre-Loaded Models (Faster Response Times)
One of the biggest challenges in decentralized inference is latency at startup.
Previously, a request would arrive, the model would load into memory, then the request would be served.
Depending on the system, this could take time. Sometimes a lot of time.
Now
Hosts can manually pre-load LLMs into memory.
- Models stay ready to serve immediately
- No cold-start delays
- Faster response times
This only happens when you explicitly choose to pre-load a model.
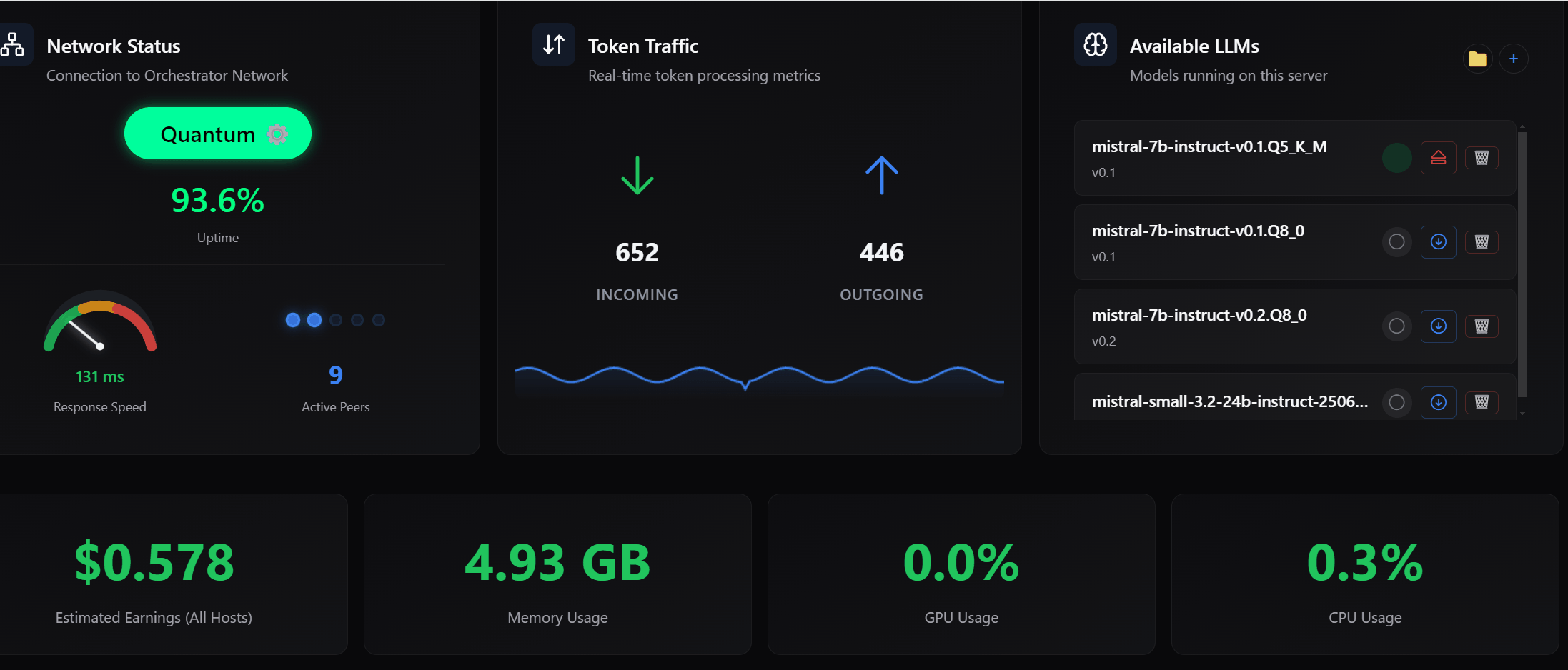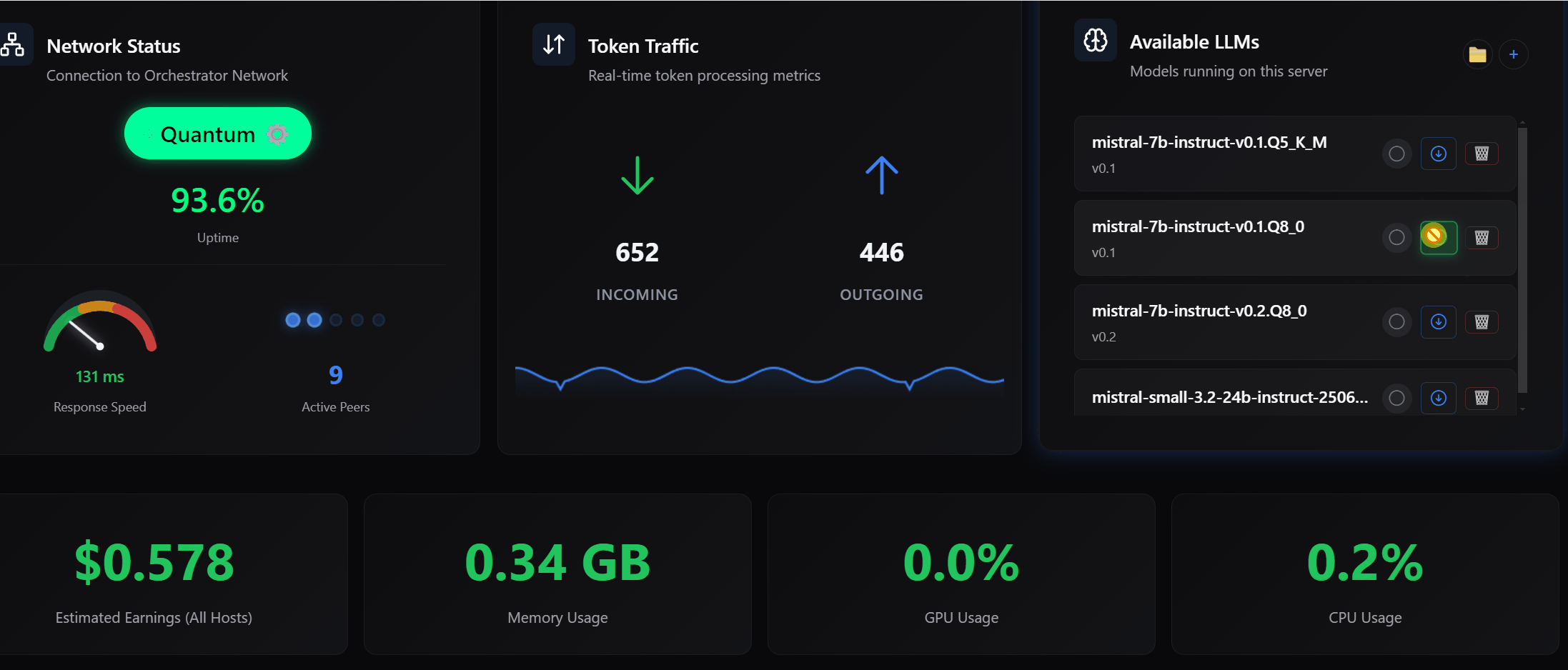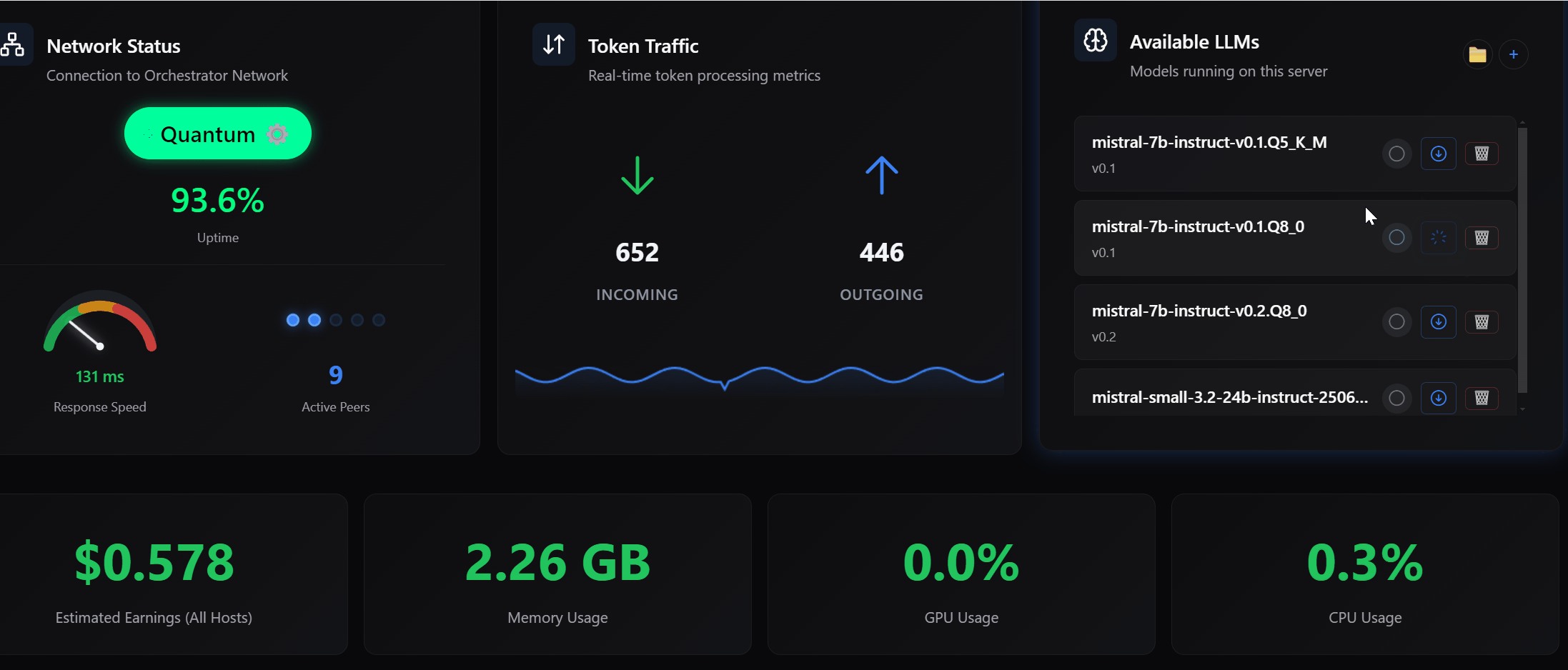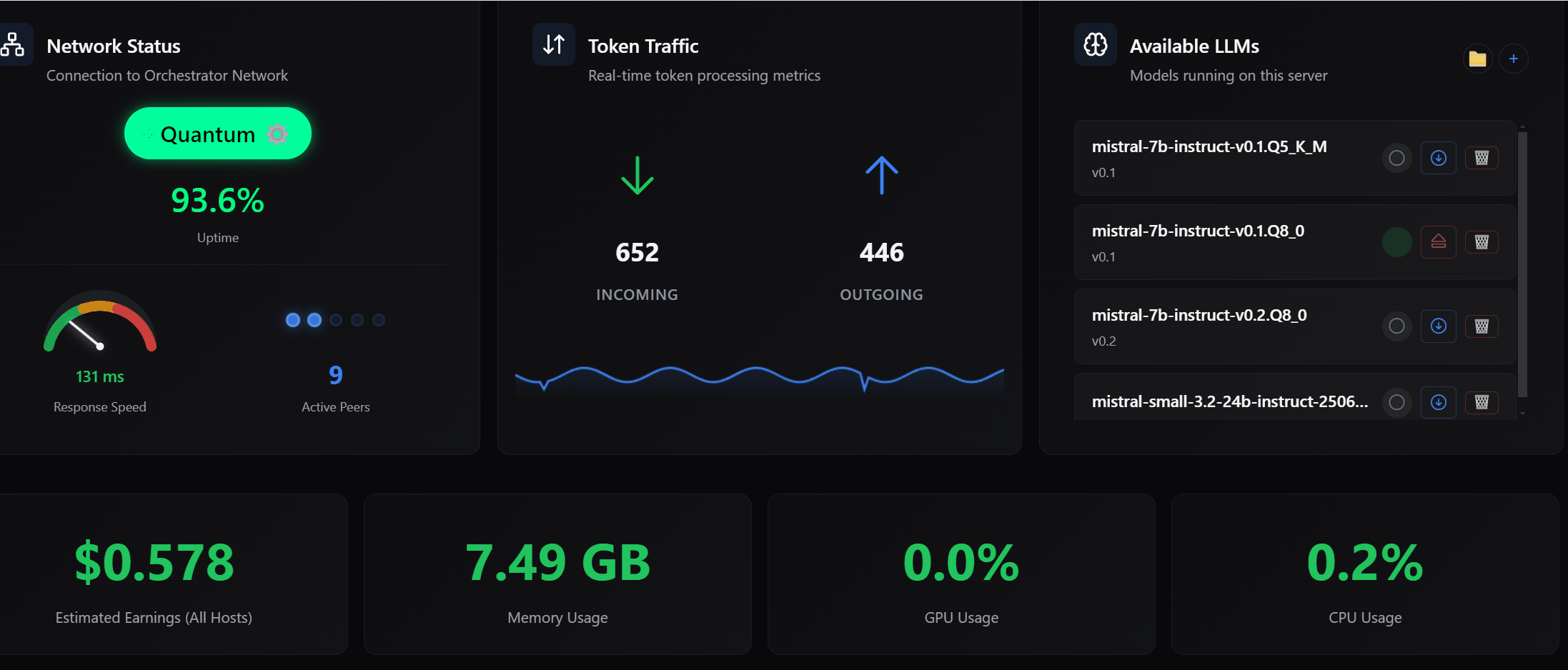
Smart Fallback Still Applies
If a model is not pre-loaded, it will still load on demand.
The network sends the task to multiple hosts and selects the fastest response available.
Even without preloading, the network remains fast and resilient.
1/ Smarter Memory Management (VRAM Protection)
Running out of VRAM is real. Especially when testing multiple models.
PeerLLM now automatically unloads models when needed.
This happens when:
- A new request requires a different model
- Memory capacity is exceeded
This means:
- No manual cleanup
- No silent failures
- The system adapts in real time
2/ Improved UI/UX for Model Awareness
You can now clearly see what is happening inside your machine.
- Which models are loaded
- Which models were manually pre-loaded
- A clearer view of your LLM inventory
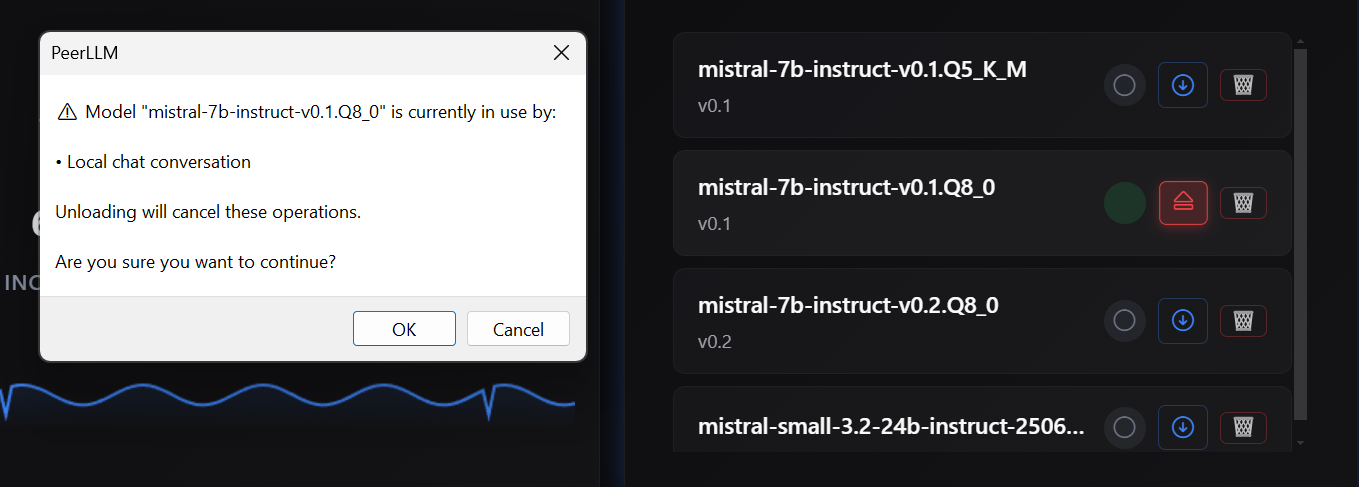
You can also unload models manually.
If there are active sessions, you will see a warning.
⚠️ Important guidance
Avoid unloading a model while there are active remote sessions.
Doing so interrupts users and may signal instability from your host.
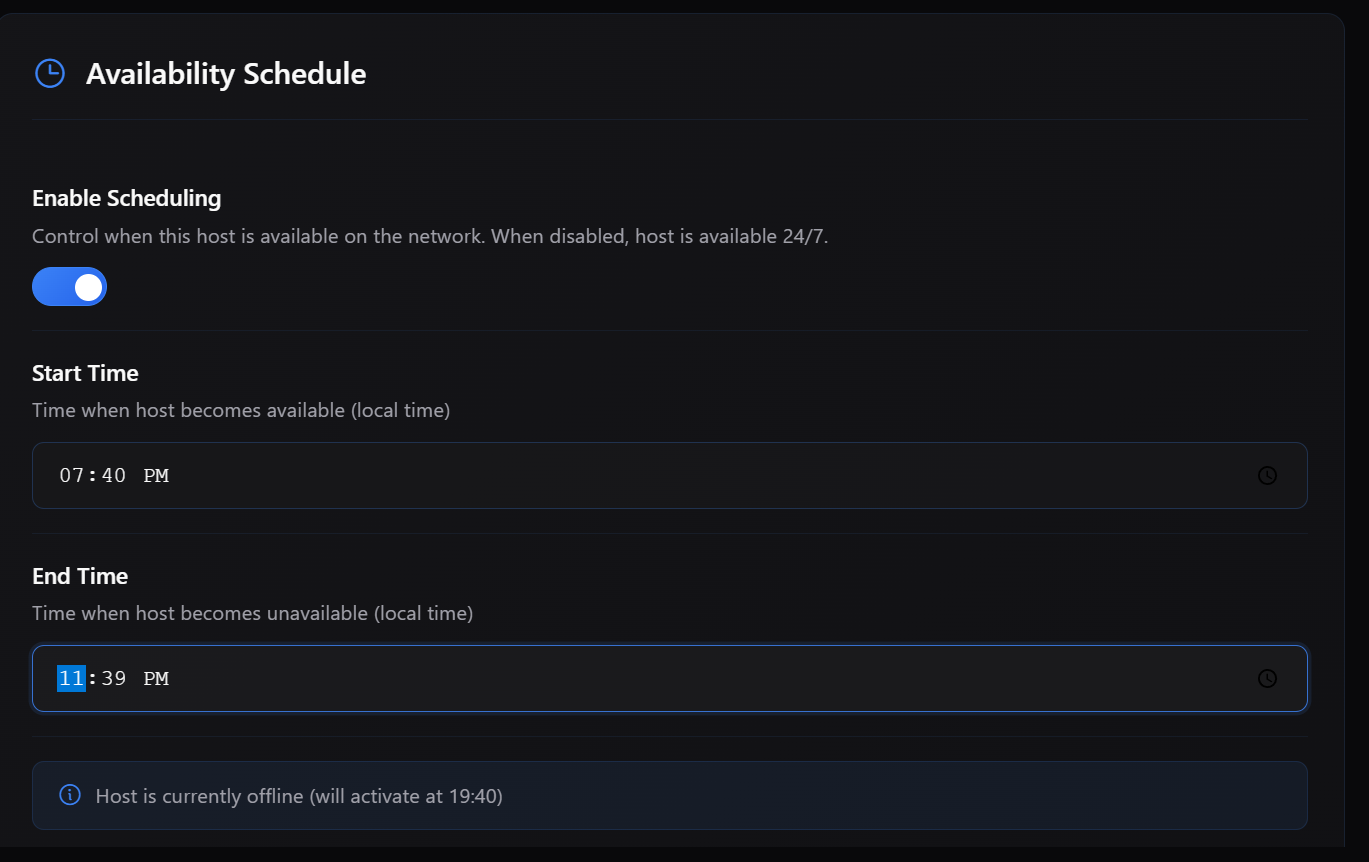
3/ Scheduled Host Availability (Previously Released, Now Official)
This feature was introduced in v1.0.0 but not announced.
Now it is official.
You can schedule when your host is online.
You can also automatically go offline during busy hours.
This is useful for shared machines, night-time usage, and predictable availability.
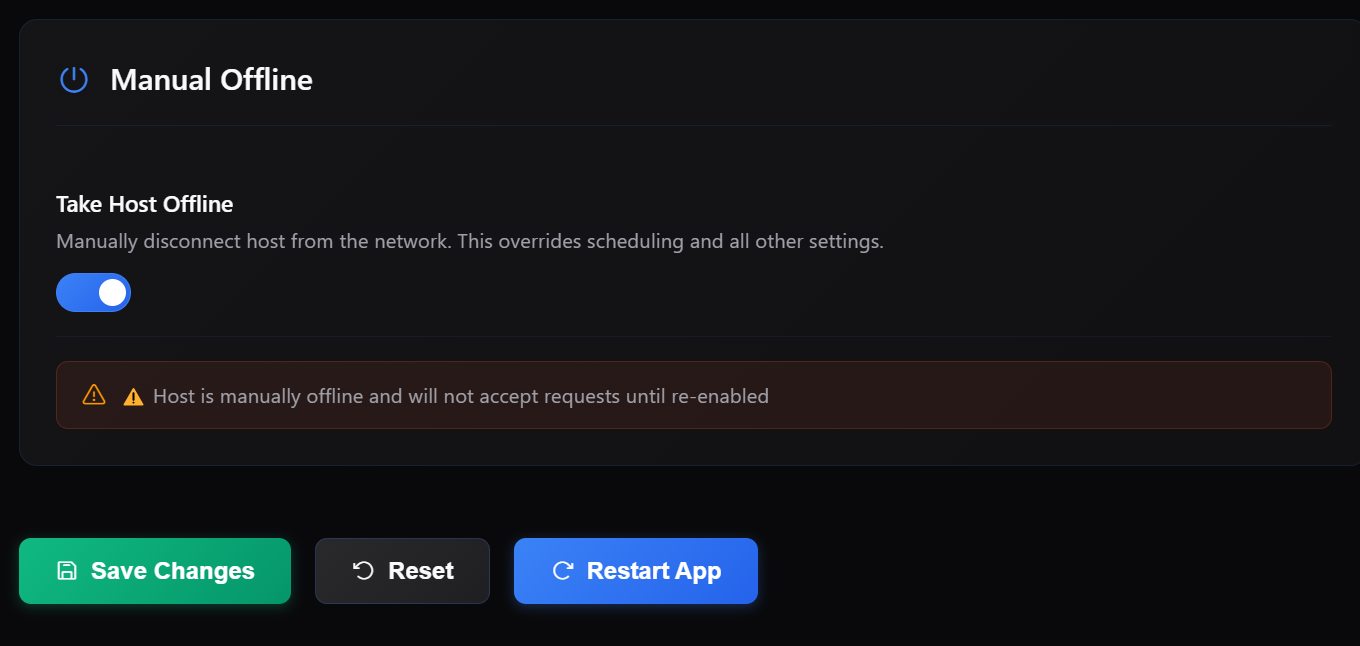
4/ Manual Offline Mode
You now have full control to go offline instantly.
- Stop receiving network traffic
- Continue using your machine locally
The host will remain offline until you bring it back online.
5/ System Tray Support (Run Quietly)
This is one of the most practical upgrades.
You can now minimize PeerLLM to the system tray.
- Keep it running without UI clutter
- Reopen or exit from a simple context menu
PeerLLM becomes:
Part of your system. Not something in your way.

6/ The Bigger Picture
PeerLLM is not just a tool.
It is a network of individuals contributing intelligence.
Right now:
- The network is live
- Hosts are generating small amounts of revenue
- This comes from compliance and validation traffic
We are now entering the next phase.
Payouts are being tested once hosts reach $25.
This is an important milestone for the network.
I want to say this clearly.
I am deeply grateful for those of you who are already running as Hosts.
Especially those subscribing at this early stage.
You are not just users of the system.
You are builders of a global decentralized intelligence.
You are one of the reasons I keep pushing forward with this project.
7/ What’s Coming Next
I am actively working with local and national businesses.
The goal is to integrate PeerLLM into real-world systems.
I expect this upcoming quarter to introduce paid business usage into the network.
This means:
- More traffic
- More value
- More opportunity for Hosts
Final Thought
Every release of PeerLLM is a step toward something bigger.
A world where intelligence is not owned, but contributed, shared, and rewarded.
And it starts with you. The Host.
Stay online.
Or don’t. Now you get to choose.
~ Hassan
2026-04-06