PeerLLM’s Next Phase: Decentralized Data as the Foundation of Intelligence
PeerLLM was never meant to be just another way to run LLMs.
Decentralized compute was the first phase. It was a foundational phase, but it was never the destination.
From the very beginning, PeerLLM was designed around a broader vision: building a fully decentralized intelligence ecosystem that does not just think, but remembers, decides, and acts, while remaining owned by the people and systems that power it.
Today, PeerLLM has a strong footing in the LLM compute phase. Individuals can host models, run inference locally or across private networks, and participate in decentralized compute without relying on centralized cloud providers.
That phase proved something critical:
Intelligence does not need to live in massive data centers to be useful.
But intelligence without data is shallow.
And intelligence without direction is dangerous.
This post introduces the Data phase and explains why it is essential to the long-term PeerLLM vision.
The Tri-Nature of Intelligence: Data, Decision, Direction
PeerLLM is built on a simple but powerful idea: intelligence has three inseparable parts.
- Data: knowledge, experience, signals, observations
- Decision: reasoning and inference through LLMs and compute
- Direction: intent, action, and execution
Compute alone only solves decision making.
True intelligence requires all three parts working together.
The long-term goal of PeerLLM is to cover:
- Data (this phase)
- Decision (compute and LLMs)
- Direction (abilities, actions, execution)
Together, these form a decentralized intelligence ecosystem capable of powering billions of daily operations, while also enabling billions of people and systems to earn income, sustain themselves, and evolve in a new AI-driven economy.
Why PeerLLM Cares About Data
The modern AI ecosystem has a structural problem.
Data is extracted, centralized, and monetized without meaningful consent.
Creators spend years producing knowledge only to see it absorbed into models that:
- provide no attribution
- offer no royalties
- give no control
- and often compete directly with the original creators
PeerLLM’s data phase is about correcting that. Not by centralizing ownership, but by ensuring no single entity ever owns the full data.
Manufacturing Data: Humans and Systems as Sources of Truth
In PeerLLM, data can be manufactured by people or systems.
- Humans contributing expertise and lived experience
- Sensors collecting agricultural, environmental, or industrial data
- Automated systems producing continuous streams of information
Data contribution can be:
- Triggered (requested knowledge)
- Voluntary (shared expertise or datasets)
- Automatic (continuous system-generated data)
Regardless of how data enters the network, the origin is always known.
The contributor is marked as the source of truth.
This phase comes with real challenges:
- How do we verify expertise?
- How do we detect originality?
- How do we prevent copyrighted or stolen material?
These are not afterthoughts. They are core problems this phase is designed to solve.
Hosting Data: Fragmentation by Design
Once data is contributed, it is never stored whole.
It is:
- Hashed
- Split into meaningless fragments
- Distributed across many independent hosts
No single machine, including the contributor’s, can reconstruct the data alone.
Three Hosting Layers
-
The Contributor
The original source of truth. -
The Network Hosts
Independent participants holding tiny, context-free fragments. -
The Orchestrator (Stitcher)
A system that knows how to temporarily assemble fragments only on demand.
Meaning exists only ephemerally during a request and is never permanently centralized.
Data Flow and Orchestration
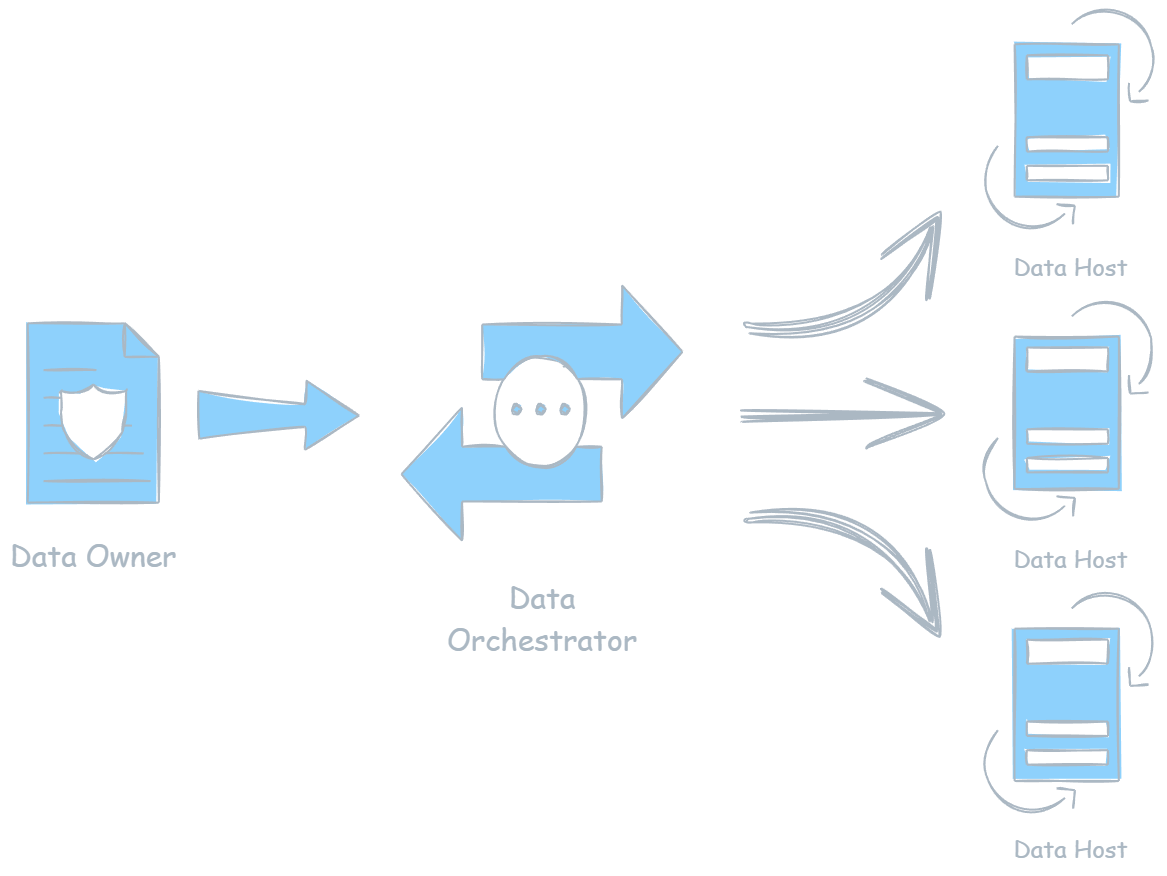
This diagram illustrates how:
- Data originates from a contributor
- Is fragmented and distributed across the network
- Is temporarily stitched together for consumption
- Then immediately released back into fragments
If any host is compromised:
- Nothing meaningful is exposed
- No dataset can be reconstructed
- No centralized target exists
Consuming Data: Three Governed Forms
Data in PeerLLM can be consumed in three distinct ways, all governed and auditable.
1. Raw Data Consumption
Direct access to raw text or raw signals for human review or specialized processing. Access is permissioned and tracked to reduce leakage.
2. LLM / Fine-Tuning Consumption
Data can be used to train or fine-tune language models, embedding contributor knowledge while preserving attribution and compensation.
3. RAG (Retrieval-Augmented Generation)
Data is retrieved dynamically. Only the fragments required to answer a question are assembled, used, and immediately released.
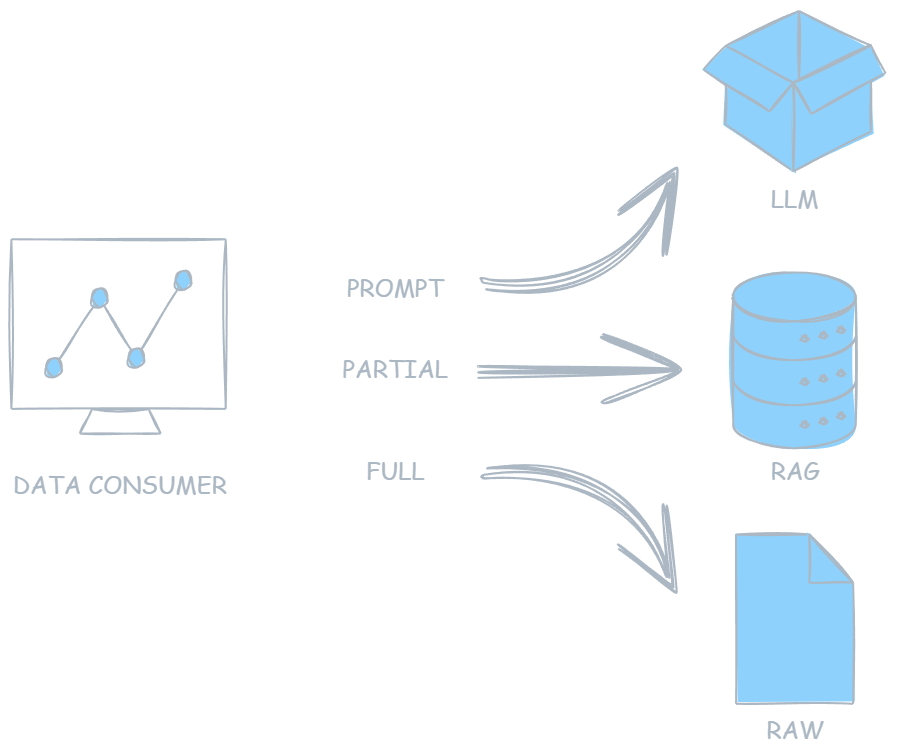
Each mode supports:
- Attribution
- Royalties or flat-fee compensation
- Policy enforcement
- Regulatory compliance
Recognizing the Challenges Ahead
This phase introduces hard problems, and we acknowledge them openly.
- Manufacturing challenges: authenticity and expertise validation
- Hosting challenges: detecting illicit data before fragmentation
- Consumption challenges: preventing misuse or off-network leakage
No system is perfect.
PeerLLM is designed to minimize harm by architecture, not by trust.
The Bigger Picture
Decentralized compute proved intelligence can be owned.
Decentralized data ensures knowledge can be shared without being stolen.
The next phase, decentralized direction, will ensure intelligence acts only where it is trusted.
Together, these phases form more than a platform.
A decentralized intelligence ecosystem that allows people and systems to participate, earn, and evolve without surrendering control to centralized power.
This is the future PeerLLM is building.
And this is only the beginning.